

10-Minute Missing Page Audit
Some of you know that I spend a lot of time behind the scenes here on Pro Q&A. One of the challenges of Q&A is that we often have to tackle complex problems in a very short amount of time – we might have 10-15 minutes to solve an issue like "Why isn't my page showing up on Google?" with no access to internal data, server-side code, etc.
Of course, I'd never suggest you try to solve your own SEO problems in just 10 minutes, but it's amazing what you can do when you're forced to really make your time count. I'd like to share my 10-minute (give or take) process for solving one common SEO problem – finding a "missing" page. You can actually apply it to a number of problems, including:
- Finding out why a page isn't getting indexed
- Discovering why a page isn't ranking
- Determining if a page has been penalized
- Spotting duplicate content problems
I'll break the 10 minutes down, minute by minute (give or take). The mini-clock on each item shows you the elapsed time, for real-time drama.
 0:00-0:30 – Confirm the site is indexed
0:00-0:30 – Confirm the site is indexed
Always start at the beginning – is your page really missing? Although it sometimes gets a bad rap for accuracy (mainly, the total page counts), Google's site: command is still the best tool for the job. It's great for deep dives, since you can combine it with keyword searches, "keyword" searches (exact match), and other operators (intitle:, inurl:, etc.). Of course, the most basic format is just:
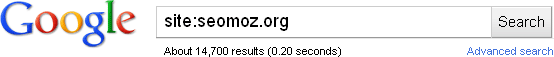
For this particular job, always use the root domain. You never know when Google is indexing multiple sub-domains (or the wrong sub-domain), and that information could come in handy later. Of course, for now you just want to see that Google knows you exist.
 0:30-1:00 – Confirm the page is not indexed
0:30-1:00 – Confirm the page is not indexed
Assuming Google knows your site exists, it's time to check the specific page in question. You can enter a full path behind the site: command or use a combination of site: and inurl:

If the page doesn't seem to be on Google's radar, narrow down the problem by testing out just "/folder" and see if anything on the same level is being indexed. If the page isn't being indexed at all, you can skip the next step.
 1:00-1:30 – Confirm the page is not ranking
1:00-1:30 – Confirm the page is not ranking
If the page is being indexed but you can't seem to find it in the SERPs, pull out a snippet of the TITLE tag and do an exact-match search (in quotes) on Google. If you still can't find it, combine a site:example.com with your page TITLE or a portion of it. If the page is indexed but not ranking, you can probably skip the next couple of steps (jump to the 4:00 mark).
 1:30-2:00 – Check for bad Robots.txt
1:30-2:00 – Check for bad Robots.txt
For now, let's assume your site is being partially indexed, but the page in question is missing from the index. Although bad Robots.txt files are, thankfully, getting rarer, it's still worth taking a quick peek to make sure you're not accidentally blocking search bots. Luckily, the file is almost always at:
http://www.example.com/robots.txt
What you're looking for is source code that looks something like this:

It could either be a directive blocking all user agents, or just one, like Googlebot. Likewise, check for any directives that disallow the specific folder or page in question.
 2:00-2:30 – Check for META Noindex
2:00-2:30 – Check for META Noindex
Another accidental blocking problem can occur with a bad META Noindex directive. In the header of the HTML source code (between <head> and </head>), you're looking for something like this:
![]()
Although it might seem odd for someone to block a page they clearly want indexed, bad META tags and Rel=Canonical (see below) can easily be created by a bad CMS set-up.
 2:30-3:00 – Check for bad Rel=Canonical
2:30-3:00 – Check for bad Rel=Canonical
This one's a bit trickier. The Rel=Canonical tag is, by itself, often a good thing, helping to effectively canonicalize pages and remove duplicate content. The tag itself looks like this:
![]()
The problem comes when you canonicalize too narrowly. Let's say for example, that every page on your site had a canonical tag with the URL "www.example.com" – Google would take that as an instruction to collapse your entire search index down to just ONE page.
Why would you do this? You probably wouldn't, on purpose, but it's easy for a bad CMS or plug-in to go wrong. Even if it's not sitewide, it's easy to canonicalize too narrowly and knock out important pages. This is a problem that seems to be on the rise.
 3:00-4:00 – Check for bad header/redirects
3:00-4:00 – Check for bad header/redirects
In some cases, a page may be returning a bad header, error code (404, for example) or poorly structured redirect (301/302) that's preventing proper indexation. You'll need a header checker for this – there are plenty of free ones online (try HTTP Web-Sniffer). You're looking for a "200 OK" status code. If you receive a string of redirects, a 404, or any error code (4xx or 5xx series), you could have a problem. If you get a redirect (301 or 302), you're sending the "missing" page to another page. Turns out, it's not really missing at all.
 4:00-5:00 – Check for cross-site duplication
4:00-5:00 – Check for cross-site duplication
There are basically two potential buckets of duplicate content – duplicate pages within your site and duplicates between sites. The latter may happen due to sharing content with your own properties, legally repurposing contents (like an affiliate marketer might do), or flat-out scraping. The problem is that, once Google detects these duplicates, it's probably going to pick one and ignore the rest.
If you suspect that content from your "missing" page has been either taken from another site or taken by another site, grab a unique-sounding sentence, and Google it with quotes (to do an exact match). If another site pops up, your page may have been flagged as a duplicate.
 5:00-7:00 – Check for internal duplication
5:00-7:00 – Check for internal duplication
Internal duplication usually happens when Google crawls multiple URL variations for the same page, such as CGI parameters in the URL. If Google reaches the same page by two URL paths, it sees two separate pages, and one of them is probably going to get ignored. Sometimes, that's fine, but other times, Google ignores the wrong one.
For internal duplication, use a focused site: query with some unique title keywords from the page (again, in quotes), either stand-alone or using intitle:. URL-driven duplicates naturally have duplicate titles and META data, so the page title is one of the easiest places to find it. If you see either the same page pop up multiple times with different URLs, or one or two pages followed by this:

...then it's entirely possible that your missing page was filtered out due to internal duplication.
 7:00-8:00 – Review anchor text quality
7:00-8:00 – Review anchor text quality
These last two are a bit tougher and more subjective, but I want to give a few quick tips for where to start if you suspect a page-specific penalty or devaluation. One pretty easy to spot problem is when you have a pattern of suspicious anchor text – usually, an uncommon keyword combination that dominates your inbound links. This could come from a very aggressive (and often low-quality) link-building campaign or from something like a widget that's dominating your link profile.
Open Site Explorer allows you to pretty easily look at your anchor text in broad strokes. Just enter your URL, click on Anchor Text Distributions (the 4th tab), and select Phrases:
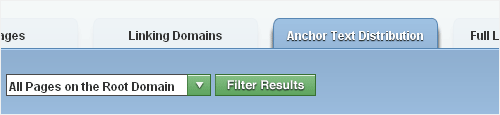
What you're looking for is a pattern of unnatural repetition. Some repetition is fine – you're naturally going to have anchor text to your domain name keywords and your exact brand name, for example. Let's say, though, that 70% of our links pointing back to SEOmoz had the anchor text "Danny Dover Is Awesome." That would be unnatural. If Google thinks this is a sign of manipulative link building, you may see that target page penalized.
 8:00-10:00 – Review link profile quality
8:00-10:00 – Review link profile quality
Link profile quality can be very subjective, and it's not a task that you can do justice to in two minutes, but if you do have a penalty in play, it's sometimes easy to spot some shady links quickly. Again, I'm going to use Open Site Explorer, and I'm going to select the following options: Followed + 301, External Pages Only, All Pages on The Root Domain:
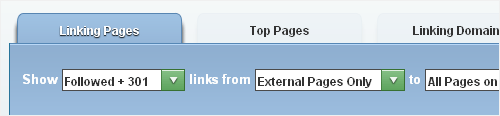
You can export the links to Excel if you want to (great for deep analysis), but for now, just spot-check. If there's something fishy on the first couple of pages, odds are pretty good that the weaker links are a mess. Click through to a few pages, looking out for issues such as:
- Suspicious anchor text (irrelevant, spammy, etc.)
- Sites with wildly irrelevant topics
- Links embedded in an obviously paid or exchanged block
- Links that are part of a multi-link page footer
- Advertising links that are followed (and shouldn't be)
Also, look for any over-reliance on one kind of low-quality link (blog comments, article marketing, etc.). Although a full link-profile analysis can take hours, it's often surprisingly easy to spot spammy link-building in just a few minutes. If you can spot it that fast, chances are pretty good that Google can, too.
(10:00) – Time's Up
Ten minutes may not seem like much (it may have taken you that long just to read this post), but once you put a process in place, you can learn a lot about a site in just a few minutes. Of course, finding a problem and solving it are two entirely different things, but I hope this at least gives you the beginning of a process to try out yourself and refine for your own SEO issues.



Comments
Please keep your comments TAGFEE by following the community etiquette
Comments are closed. Got a burning question? Head to our Q&A section to start a new conversation.