

17 Ways Search Engines Judge the Value of a Link
It's 9:30am and you've just started a pitch for a new SEO client. They're the curious type - wanting to know how search engines rank pages, why the changes you'll recommend will make an impact, where you learned to do SEO, and who you can list as good examples of your work. As you dive deeper into the requirements for the project, you arrive at the link building section. The client wants to know why link building matters so much. You pull up a chart of Search Engine Ranking Factors, noting the large role that links play in the ordering algorithms. They're mollified, but have one last question:
How does Google decide how much a particular link helps my rankings?
That's where this blog post comes in handy. Below, you'll find a list of many of the most important factors the engines consider when judging the value of a link.
Before we start, there's one quick concept that's critical to grasp:
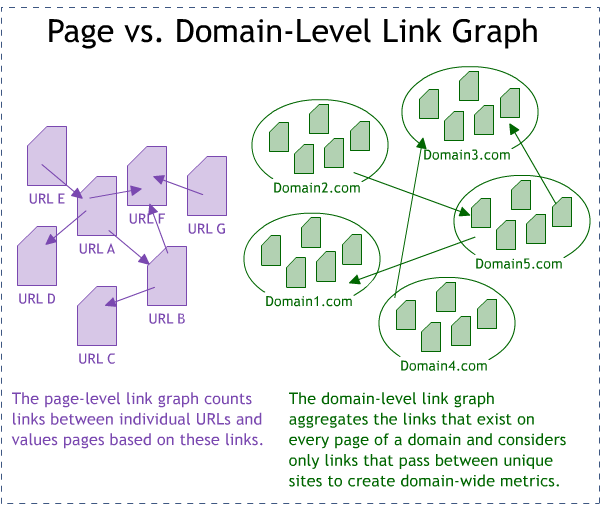
As you've likely noticed, search engines have become more and more dependent on metrics about an entire domain, rather than just an individual page. It's why you'll see new pages or those with very few links ranking highly, simply because they're on an important, trusted, well-linked-to domain. In the ranking factors survey, we called this "domain authority" and it accounted for the single largest chunk of the Google algorithm (in the aggregate of the voters' opinions). Domain authority is likely calculated off the domain link graph, which is unique from the web's page-based link graph (upon which Google's original PageRank algorithm is based). In the list below, some metrics influence only one of these, while others can affect both.
#1 - Internal vs. External
When search engines first began valuing links as a way to determine the popularity, importance and relevance of a document, they found the classic citation-based rule that what others say about you is far more important (and trustworthy) than what you say about yourself. Thus, while internal links (links that point from one page on your site to another) do carry some weight; links from external sites matter far more.
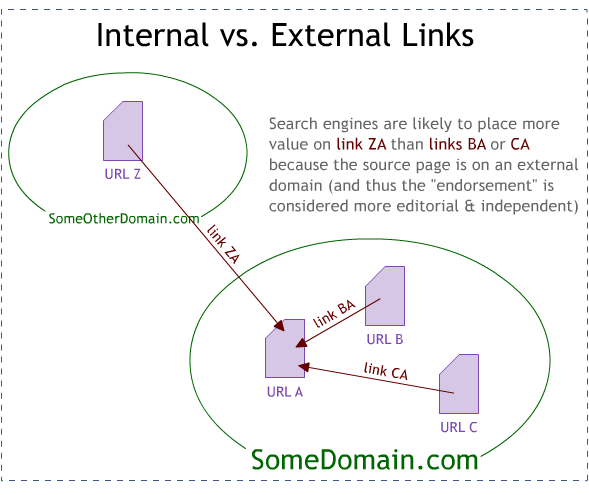
This doesn't mean it's not important to have a good internal link structure, or to do all that you can with your internal links (good anchor text, no unnecessary links, etc.), it just means that a site/page's performance is highly dependant on how other sites on the web have cited it.
#2 - Anchor Text
An obvious one for those in the SEO business, anchor text is one of the biggest factors in the rankings equation overall, so it's no surprise it features prominently in the attributes of a link that engines consider.

In our experiments (and from lots of experience), it appears that "exact match" anchor text is more beneficial than simply inclusion of the target keywords in an anchor text phrase. On a personal note, it's my opinion that the engines won't always bias in this fashion; it seems to me that, particularly for generic (non-branded) keyword phrases, this is the cause of a lot of manipulation and abuse in the SERPs.
#3 - PageRank
Whether they call it StaticRank (Microsoft's metric), WebRank (Yahoo!'s), PageRank (Google's) or mozRank (Linkscape's), some form of an iterative, Markov-chain based link analysis algorithm is a part of all the engines' ranking systems. PageRank et al. uses the analogy that links are votes and that those pages which have more votes have more influence with the votes they cast.
The nuances of PageRank are well covered in The Professional's Guide to PageRank Optimization, but, at a minimum, understanding of the general concepts is critical to being an effective SEO:
-
Every URL is assigned a tiny, innate quantity of PageRank
-
If there are "n" links on a page, each link passes that page's PageRank divided by "n" (and thus, the more links, the lower the amount of PageRank each one flows)
-
An iterative calculation that flows juice through the web's entire link graph dozens of times is used to reach the calculations for each URL's ranking score
-
Representations like those shown in Google's toolbar PageRank or SEOmoz's mozRank on a 0-10 scale are logarithmic (thus, a PageRank/mozRank 4 has 8-10X the link importance than a PR/mR 3)
PageRank can be calculated on the page-level link graph, assigning PageRank scores to individual URLs, but it can also apply to the domain-level link graph, which is how metrics like Domain mozRank (DmR) are derived. By counting only links between domains (and, to make a crude analogy, squishing together all of the pages on a site into a single list of all the unique domains that site points to), Domain mozRank (and the search engine equivalents) can be used to determine the importance of an entire site (which is likely to be at least a piece of how overall domain authority is generated).
#4 - TrustRank
The basics of TrustRank are described in this paper from Stanford - Combatting Webspam with TrustRank. The basic tenet of TrustRank is that the web's "good" and "trustworthy" pages tend to be closely linked together, and that spam is much more pervasive outside this "center." Thus, by calculating an iterative, PageRank-like metric that only flows juice from trusted seed sources, a metric like TrustRank can be used to predictively state whether a site/page is likely to be high quality vs. spam.
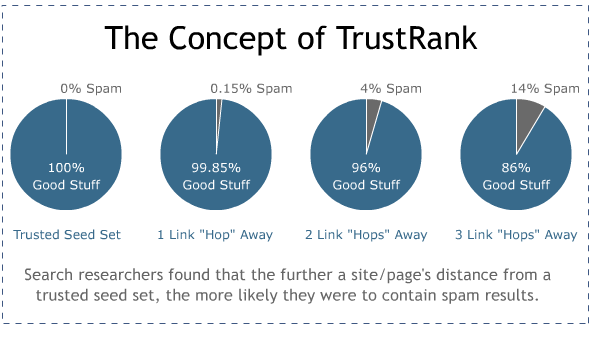
While the engines don't expose any data points around this particular metric, it's likely that some form of the "distance from trusted seeds" logic is applied by ranking algorithms. Another interesting point on TrustRank - Reverse TrustRank, which measures who links to known spam sites, is likely also part of the engines' metrics set. As with PageRank (above), TrustRank (and Reverse TrustRank) can be calculated on both the page-level and domain-level link graph. Linkscape uses this intuition to build mozTrust (mT) and Domain mozTrust (DmT), though our team feels that we still have a lot of work to do in refining these metrics for the future.
The key takeaways are fairly intuitive - get links from high trust sites and don't link to potential spam.
#5 - Domain Authority
Though the phrase "domain authority" is often discussed in the SEO world, a formal, universal definition doesn't yet exist. Most practitioners use it to describe a combination of popularity, importance and trustworthiness calculated by the search engines and based largely on link data (though some also feel the engines may use the age of the site here as well).
Search engines likely use scores about the "authority" of a domain in counting links, and thus, despite the fuzzy language, it's worth mentioning as a data point. The domains you earn links from are, potentially, just as important (or possibly more important) than the individual metrics of the page passing the link.
#6 - Diversity of Sources
In our analysis of correlation data, no single metric has a more positive a correlation with high rankings than the number of linking root domains. This appears to be both a very hard metric to manipulate for spam (particularly if you need domains of high repute with diverse link profiles of their own) and a metric that indicates true, broad popularity and importance. You can see a list of top pages and top domains on the web ordered by the number of unique root domains with links to them via Linkscape's Top 500.
Although correlation is not causation, the experience of many SEOs along with empirical data suggests that a diversity of domains linking to your site/page has a strong positive effect on rankings. By this logic, it follows that earning a link from a site that's already linked to you in the past is not as valuable as getting a link from an entirely unique domain. This also suggests that, potentially, links from sites and pages who have themselves earned diverse link profiles, may be more trusted and more valuable than those from low diversity sources.
#7 - Uniqueness of Source + Target
The engines have a number of ways to judge and predict ownership and relationships between websites. These can include (but are certainly not limited to):
- A large number of shared, reciprocated links
- Domain registration data
- Shared hosting IP address or IP address C-blocks
- Public acquisition/relationship information
- Publicized marketing agreements that can be machine-read and interpreted
If the engines determine that a pre-existing relationship of some kind could inhibit the "editorial" quality of a link passing between two sites, they may choose to discount or even ignore these. Anecdotal evidence that links shared between "networks" of websites pass little value (particularly the classic SEO strategy of "sitewide" links) is one point many in the organic search field point to on this topic.
#8 - Location on the Page
Microsoft was the first engine to reveal public data about their plans to do "block-level" analysis (in an MS Research piece on VIPS - VIsion-based Page Segmentation).
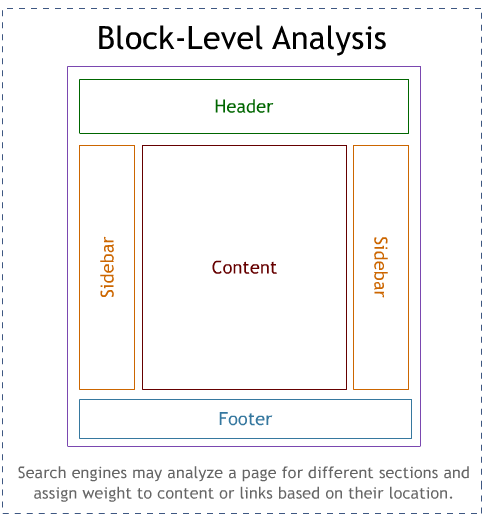
Since then, many SEOs have reported observing the impact of analysis like this from Google & Yahoo! as well. It appears to us at SEOmoz, for example, that internal links in the footer of web pages may not provide the same beneficial results that those same links will when placed into top/header navigation. Others have reported that one way the engines appear to be fighting pervasive link advertising is by diminishing the value that external links carry from the sidebar or footer of web pages.
SEOs tend to agree on one point - that links from the "content" of a piece is most valuable, both from the value the link passes for rankings and, fortuitously, for click-through traffic as well.
#9 - Topical Relevance
There are numerous ways the engines can run topical analysis to determine whether two pages (or sites) cover similar subject matter. Years ago, Google Labs featured an automatic classification tool that could predict, based on a URL, the category and sub-category for virtually any type of content (from medical to real estate, marketing, sports and dozens more). It's possible that engines may use these automated topical-classification systems to identify "neighbourhoods" around particular topics and count links more or less based on the behaviour they see as accretive to their quality of ranking results.
I personally don't worry too much about topical relevance - if you can get a link from a topic agnostic site (like NYTimes.com) or a very specific blog on a completely unrelated subject (maybe because they happen to like something you published), I'm bullish that these "non-topic-specific" endorsements are likely to still pass positive value. I think it's somewhat more likely that the engines might evaluate potential spam or manipulative links based on these analyses. A site that's never previously linked-to pharmaceutical, gambling or adult topic regions may appear as an outlier on the link graph in potential spam scenarios.
#10 - Content & Context Assessment
Though topical relevance can provide useful information for engines about linking relationships, it's possible that the content and context of a link may be even more useful in determining the value it should pass from the source to the target. In content/context analysis, the engines attempt to discern, in a machine parse-able way, why a link exists on a page.
When links are meant editorially, certain patterns arise. They tend to be embedded in the content, link to relevant sources, use accepted norms for HTML structure, word usage, phrasing, language, etc. Through detailed pattern-matching and, potentially, machine learning on large data sets, the engines may be able to form distinctions about what constitutes a "legitimate" and "editorially-given" link that's intended as an endorsement vs. those that may be placed surreptitiously (through hacking), those that are the result of content licensing (but carry little other weight), those that are pay-for-placement, etc.
#11 - Geographic Location
The geography of a link is highly dependent on the perceived location of its host, but the engines, particularly Google, have been getting increasingly sophisticated about employing data points to pinpoint the location-relevance of a root domain, subdomain or subfolder. These can include:
- The host IP address location
- The country-code TLD extension (.de, .co.uk, etc)
- The language of the content
- Registration with local search systems and/or regional directories
- Association with a physical address
- The geographic location of links to that site/section
Earning links from a page/site targeted to a particular region may help that page (or your entire site) to perform better in that region's searches. Likewise, if your link profile is strongly biased to a particular region, it may be difficult to appear prominently in another, even if other location-identifying data is present (such as hosting IP address, domain extension, etc).
#12 - Use of Rel="Nofollow"
Although in the SEO world it feels like a lifetime ago since nofollow appeared, it's actually only been around since January of 2005, when Google announced it was adopting support for the new HTML tag. Very simply, rel="nofollow", when attached to a link, tells the engines not to ascribe any of the editorial endorsements or "votes" that would boost a page/site's query independent ranking metrics. Today, Linkscape's index notes that approximately 3% of all links on the web are nofollowed, and that of these, more than half are sites using nofollow on internal, rather than external pointing links.
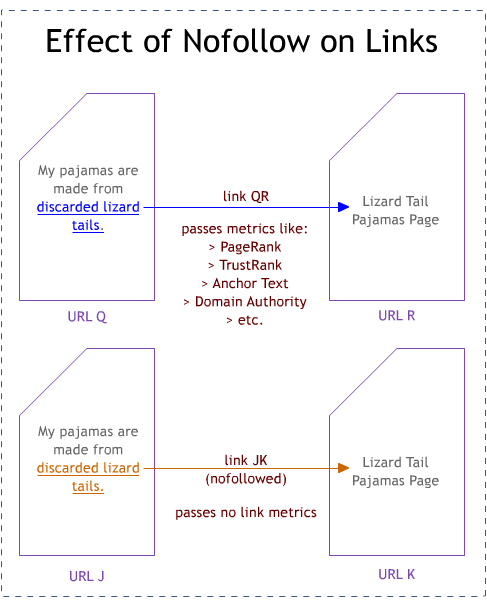
Some question exists in the SEO field as to whether, and how strictly, each individual engine follows this protocol. It's often been purported, for example, that Google may still pass some citation quality through Wikipedia's external links, despite the use of nofollow.
#13 - Link Type
Links can come in a variety of formats. The big three are:
- Straight HTML Text Links
- Image Links
- Javascript Links
Google recently announced that they're not only crawling this third group, but passing link endorsement metrics through them (which has many upset about the reversal in policy about using Javascript as a way to delineate paid/advertising links). For years now, they've also treated the text in an image's alt attribute in a similar fashion to how anchor text is handled in standard text links.
However, not all links are treated equally. In both anecdotal examples and testing, it appears that straight, HTML links with standard anchor text pass the most value, followed by image links with keyword-rich alt text and finally, Javascript links (which still aren't universally followed or considered as an endorsement, at least in our experience). Link builders, content licensers, badge and widget creators and those who enable embeddable content should all, in my opinion, assume the worst about the engines' ability to handle and pass value from non-standard links and aim to get HTML text links with good anchor text as an optimal methodology.
#14 - Other Link Targets on the Source Page
When a page links out externally, both the quantity and targets of the other links that exist on that page may be taken into account by the engines when determining how much link juice should pass.
As we've already mentioned above (in item #3), the "PageRank"-like algorithms from all the engines (and SEOmoz's mozRank) divide the amount of juice passed by any given page by the number of links on that page. In addition to this metric, the engines may also consider the quantity of external domains a page points to as a way to judge the quality and value of those endorsements. If, for example, a page links to only a few external resources on a particular topic, spread out amongst the content, that may be perceived differently than a long list of links pointing to many different external sites. One is not necessarily better or worse than the other, but it's possible the engines may pass greater endorsement through one model than another (and could use a system like this to devalue the links sent from what they perceive to be low-value-add directories).
The engines are also very likely to be looking at who else a linking page endorses. Having a link from a page that also links to low quality pages that may be considered spam is almost certainly less valuable than receiving links from pages that endorse and link out to high quality, reputable domains and URLs.
#15 - Domain, Page & Link-Specific Penalties
As nearly everyone in the SEO business is aware (though those in the tech media may still be a bit behind), search engines apply penalties to sites and pages ranging from the loss of the ability to pass link juice/endorsement all the way up to a full ban from their indices. If a page or site has lost its ability to pass link endorsements, acquiring links from it provides no algorithmic value for search rankings. Be aware that the engines sometimes show penalties publicly (inability to rank for obvious title/URL matches, lowered PageRank scores, etc.) but continue to keep these penalties inconsistent so systemic manipulators can't acquire solid data points about who can gets "hit" vs. not.
#16 - Content/Embed Patterns
As content licensing & distribution, widgets, badges and distributed, embeddable links-in-content become more prevalent across the web, the engines have begun looking for ways to avoid becoming inundated by these tactics. I don't believe that the engines don't want to count the vast majority of links that employ these systems, but they're also wary about over-counting or over-representing sites that simply do a good job getting distribution of a single badge/widget/embed/licensing-deal.
To that end, here at SEOmoz, we think it's likely that content pattern detection and link pattern detection plays a role in how the engines evaluate link diversity and quality. If the search engines see, for example, the same piece of content with the same link across thousands of sites, that may not signal the same level of endorsement that a diversity of unique link types and surrounding content would provide. The "editorial" nature of a highly similar snippet compared to those of clearly unique, self-generated links may be debatable, but from the engines' perspectives, being able to identify and potentially filter links using these attributes is a smart way to future-proof against manipulation.
#17 - Temporal / Historical Data
Timing and data about the appearance of links is the final point on this checklist. As the engines crawl the web and see patterns about how new sites, new pages and old stalwarts earn links, they can use this data to help fight spam, identify authority and relevance and even deliver greater freshness for pages that are rising quickly in link acquisition.
How the engines use these patterns of link attraction is up for debate and speculation, but the data is almost certainly being consumed, processed and exploited to help ranking algorithms do a better job of surfacing the best possible results (and reducing the abilities of spam - especially large link purchases or exploits - to have an impact on the rankings).
While the list above includes many data points, it's almost certainly not comprehensive. Please feel free to suggest others that belong here in the comments below.
The author's views are entirely their own (excluding the unlikely event of hypnosis) and may not always reflect the views of Moz.



Comments
Please keep your comments TAGFEE by following the community etiquette
Comments are closed. Got a burning question? Head to our Q&A section to start a new conversation.