

Building The Implicit Social Graph
The author's views are entirely their own (excluding the unlikely event of hypnosis) and may not always reflect the views of Moz.
Google Plus is Google's latest attempt at building an explicit social graph that they control, but Google has been building out an implicit social graph for quite some time. This graph is still relatively naive compared to the maturity of the link graph, but search engines continue to develop this graph. Since it is already directly influencing rankings, and its value will increase, it’s important to understand how this type of social graph is being built. In this post, I’ll look at some of the methods for building the social graph, as well as looking at explicit vs. implicit social graphs.
You can be certain Google is building an implicit social graph:
“we studied the implicit social graph, a social network that is constructed by the interactions between users and their groups. We proposed an interaction-based metric for computing the relative importance of the contacts and groups in a user's egocentric network, that takes into account the recency, frequency, and direction of interactions” - Google
Building the Implicit Graph
This graph can be built by looking at Google’s link graph.
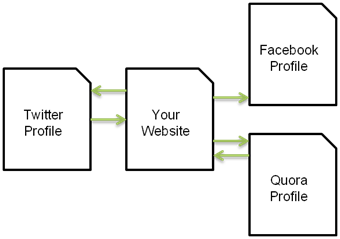
By looking at links between profiles, and reinforcing relationships based off content analysis (username, bio, etc), search engines can confirm ownership, or at least believe with a high degree of certainty that all of these web properties are in fact owned by one person.
The implicit graph can grow from one seed explicit relationship.
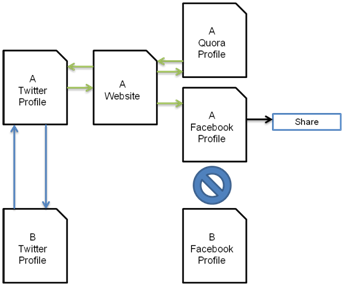
In this example, accounts A and B have defined an explicit relationship via reciprocal following on Twitter. The degree of this relationship can be gauged on interactions, but more on that in a moment. However, A and B have not continued this relationship across all networks, such as Facebook (or maybe the relationship is not crawlable).
Let’s say for example I’m user B and user A is Hello Kitty. Hello Kitty shares a link publicly on Facebook, and then later I perform the following search.
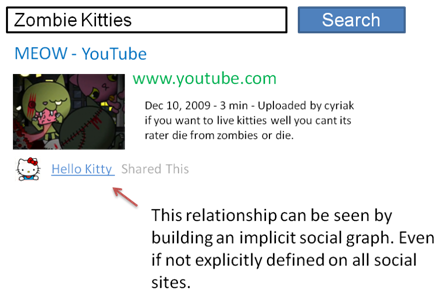
The explicit relationship on one social network can be used to evaluate URLs based off the behavior on a different social network where I have not explicitly defined it. This brings up all sorts of questions about privacy, and Google will tread lightly here, as you don’t want Google displaying known relationships that you haven’t made public. However, displaying and knowing are independent. They might know your relationships, even if they never expose them to you.
In the Google paper “Suggesting (More) Friends Using the Implicit Social Graph” they clearly make a distinction here:
“we draw a sharp distinction between each user's egocentric network and the global or sociocentric network that is formed by combining the networks of all users. […] By showing users suggestions based only on their local data, we are able to protect user privacy and avoid exposing connections between the user's contacts that might not otherwise have been known to him”
Interaction Rank
Relationships can be further analyzed by computing Interaction Rank, which measures the degree of relationship between two users.
Interaction Rank: A metric computed by looking at the number of exchanges between users, weighting each interaction as a function of recency. The interaction weight decays exponentially over time. It also looks at the relative importance of ongoing interactions.
Note: In the paper, Interaction Rank is defined in terms of building an implicit social network on top of email interactions, which is a data set Google has a lot of access to, but could be applied to non-email social graphs.
Google may use three criteria to measure edge weights. In graph theory, edges are the connections between nodes (the blue lines in the image above).
1. Frequency: Users / groups that interact frequently are more important to those with infrequent interactions.
2. Recency: The change in interactions over time. Recent interactions should carry more weight than interactions in the past.
3. Direction: Interactions a user initiates are more significant than those a user does not initiate.
Criteria like direction, for example, can help determine spam relationships. Spam accounts send out more interactions than they receive.
One obvious short-coming of the model is that Interaction Rank is higher for active social media users than less active users. However, since Interaction Rank is used to sort relationships relative to one egocentric view of the graph, and not across a global graph, it can function as metric to sort the relative importance of relationships in regards to the central node/user.
They’ve Been Doing This for a Long Time
Google is getting a lot more attention regarding social recently, but Google has been doing this for quite some time. Google launched the Social Graph API back in February of 2008, which is an API that taps into one form of an explicit graph based off XFN and FOAF. This tool has been tracking reciprocal Twitter relationships, and many other things, for years.

Some of the social network building they’ve done can be seen via the social graph API.
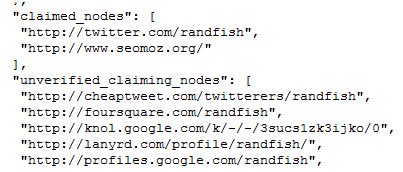
Rand gave examples back in July of this type of deep dive crawl.
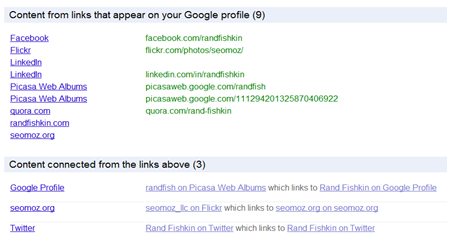
They crawl from this seed set of explicit opt-ins to build out a wider set of related connections.
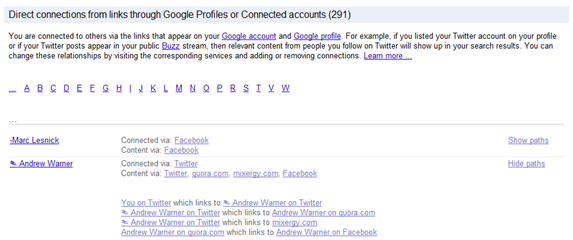
In the example above, Google is crawling multiple hops away from a seed node to build out an implicit social graph. In the example above, a relationship between Rand and Andrew can be defined, and this relationship analysis can be carried over to networks where that relationship isn’t explicitly defined. The Interaction Rank between Rand and Andrew on Twitter can set the degree that Google pulls signals from these implicit connections.
And Here Comes Google Circles
This all changes with Google Plus. One of the limitations of building an implicit social graph is that you don’t have the data to test against to confirm the predictions and relationships that graph discovers. It still has to depend on the data made public, but is limited by relationships that are held private (aka Facebook). Google Plus, among other things, creates a massive set of explicit social graph data, which can be used for machine learning and accuracy checking.
It’s easy to imagine that Google will use the implicit social graph to predict relationships with relative degrees of certainty about the nature and importance of that relationship. Now Google Plus data can be pushed into the algo, in the same way human reviews could be pushed into Panda. And not only that, but they’re bucketed into contextual based relationships using Circles. The implications of this are huge.
However, an explicit social network will not replace the implicit network.
From the same Google paper:
“One survey of mobile phone users in Europe showed that only 16% of users have created custom contact groups on their mobile phones. In our user studies, users explain that group-creation is time consuming and tedious. Additionally, groups change dynamically, with new individuals being added to multi-party communication threads and others being removed. Static, custom-created groups can quickly become stale, and lose their utility”
They go on to say:
“Our algorithm is inspired by the observation that, although users are reluctant to expend the effort to create explicit contact groups, they nonetheless implicitly cluster their contacts into groups via their interactions with them”
This clearly shows at least some of the shortcomings of the explicit social graph.
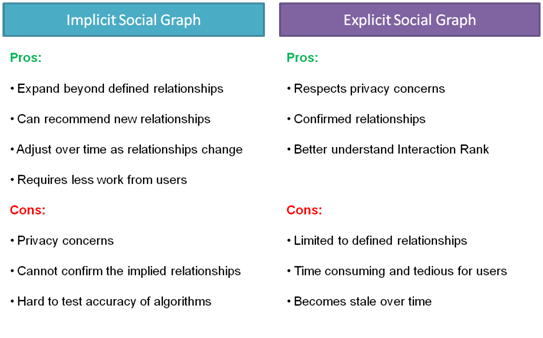
Even with publicly available, and privately available, explicit social data, there is still a strong incentive to build out the implicit graph. The explicit graph can be used to make improvements upon this graph. The implicit graph is one area where Google has a significant advantage over Facebook.
It’s no secret that the social graph appears to be the next evolution with increasing uses of social factors, social elements in search, and mechanisms that will lead into AgentRank/AuthorRank, which will tie directly into the implicit social graph.
p.s. Some great additional reading on this topic: Are You Trusted by Google? via SEO By the Sea's Bill Slawski.


Comments
Please keep your comments TAGFEE by following the community etiquette
Comments are closed. Got a burning question? Head to our Q&A section to start a new conversation.