
Diagnosing Google Crawl Allowance Using Webmaster Tools & Excel
The author's views are entirely their own (excluding the unlikely event of hypnosis) and may not always reflect the views of Moz.
There's been some talk recently in the SEO industry about 'crawl allowance' - it's not a new concept but Matt Cutts recently talked about it openly with Eric Enge at StoneTemple (and you can see Rand's illustrated guide too). One big question however is how do you understand how Google is crawling your site? While there are a variety of different ways of measuring this (log files is one obvious solution) the process I'm outlining in this post can be done with no technical knowledge - all you need is:
- A verified Google webmaster central account
- Google Analytics
- Excel
If you want to go down the log-file route then these two posts from Ian Lurie on how to read log files & analysing log files for SEO might be useful. It's worth pointing out however that just because Googlebot crawled a page it doesn't necessarily mean that it was actually indexed. This might seem weird but if you've ever looked in log files you'll see that sometimes Googlebot will crawl an insane number of pages but it often takes more than one visit to actually take a copy of the page and store it in it's cache. That's why I think the below method is actually quite accurate, by using a combination of URLs receiving at least 1 visit from Google and pages with internal links as reported by webmaster central. Still, taking your log file data and adding it into the below process as a 3rd data set would make things better (more data = good!).
Anyway, enough theory, here's a non technical step by step process to help you understand which pages Google is crawling on your site and compare that to which pages are actually getting traffic.
Step 1 - Download the internal links
Go to webmaster central and navigate to the "internal links" section:
Then, once you're on the internal links page click "download this table":
This will give you the table of pages which Google sees internal links to. Note - for the rest of this post I'm going to be treating this data as an estimate of Google's crawl. See a brief discussion about this at the top of the post. I feel it's more accurate than using a site: search in Google. It does have some pitfalls however since what this report is actually telling you is the number of pages with links to them, not the pages which Google has crawled. Still, it's not a bad measure of Google's index and only really becomes inaccurate when there are a lot of nofollowed internal links or pages blocked by robots.txt (which you link to).
Step 2 - Grab your landing pages from Google Analytics
This step should be familiar to all of you who have Google Analytics - go into your organic Google traffic report from the last 30 days, display the landing pages and download the data.
Note that you need to add "&limit=50000" into the URL before you hit "export as CSV" to ensure you get the as much data a possible. If you have more than 50000 landing pages then I suggest you either try a shorter date range or a more advanced method (see my reference to log files above).
Step 3 - Put both sets of data in excel
Now you need to put both of these sets of data into excel - I find it helpful to put all of the data into the same sheet in Excel but it's not actually necessary. You'll have something like this with link data for your URLs from webmaster central on the left and the visits data from Google Analytics on the right:

Step 4 - Vlookup ftw
Gogo gadget vlookup! The vlookup function was made for data sets like this and easily lets you look up the values in one data set against another data set. I advise running a vlookup twice for each data set so we get something like this:

Note - that there may be some missing data in here depending on how fresh the content is on your site (this is possibly enough room for a whole separate post on this topic) so you should then find and replace '#N/A' with 0.
Step 5 - Categorise your urls
Now, for the purposes of this post we're not interested in a URL by URL approach, we're instead looking at a high level analysis of what's going on so we want to categorise our URLs. Now, the more detail you can go into at this step the better your final data output will be. So go ahead and write a rule in excel to assign a category to your URLs. This could be anything from just following a folder structure or it could be more complex based on query string etc. It really depends on how your site structure works as to the best way of doing it so I can't write this rule for you unfortunately. Still, once this is done you should see something like this:
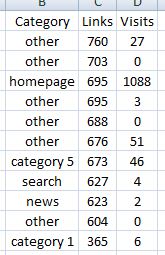
If you're struggling to build an excel rule for your pages and your site follows a standard site.com/category/sub-category/product URL template then a really simple categorisation would be to just count the number of '/'s in the URL. It won't tell you which category the URL belongs to but it will at least give you a basic categorisation of which level the page sits at. I really do think it's worth the effort to a) learn excel and b) categorise your URLs well. The better data you can add at this stage the better your results will be.
Step 6 - Pivot table Excel Ninja goodness
Now, we need the magic of pivot tables to come to our rescue and tell us the aggregated information about our categories. I suggest that you pivot both sets of data separately to get the data from both sources. Your pivot should look something like this for both sets of data:
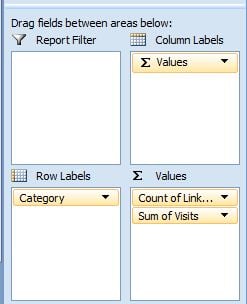
It's important to note here that what we're interested in is the COUNT of the links from webmaster central (i.e. the number of pages indexed) rather than the SUM (which is the default). Doing this for both sets of data will give you something like the following two pivots:
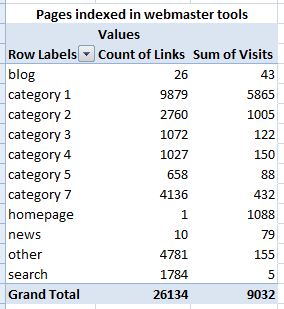
And:
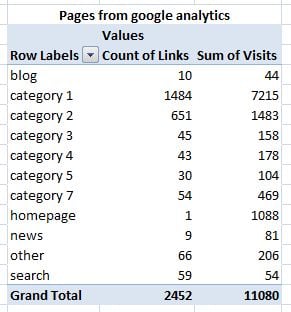
Step 7 - Combine the two pivots
Now what we want to do is take the count of links from the first pivot (from webmaster central) and the sum of the visits from the second pivot (from Google Analytics), to produce something like this:
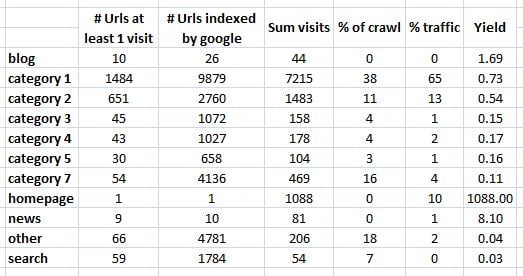
Generating the 4 columns on the right is really easy by just looking at the percentages and ratios of the first 3 columns.
Conclusions
25% of the crawl allowance accounts for only 2% of the overall organic traffic
So, what should jump out at us from this site here is that the 'search' pages and 'other' pages are being quite aggressively crawled with 25% of the overall site crawl between them yet they only account for 2% of the overall search traffic. Now in this particular example this might seem like quite a basic thing to highlight - afterall a good SEO will be able to spot search pages being crawled by doing a site review but being able to back this up with data makes for good management-friendly reports and will also help analyse the scope of the problem. What this report also highlights is that if your site is maxing out it's crawl allowance then reclaiming that 25% of your crawl allowance from search pages may lead to an increase in the number of pages crawled from your category pages which are the pages which pull in good search traffic.
Update: Patrick from Branded3 has just written a post on this very topic - Patrick's approach using separate XML sitemaps for different site sections is well worth a read and complements what I've written about here very nicely.


Comments
Please keep your comments TAGFEE by following the community etiquette
Comments are closed. Got a burning question? Head to our Q&A section to start a new conversation.