
Does Google Use Facebook Shares to Influence Search Rankings?
Intro from Rand - this post comes from Dr. Matt Peters, SEOmoz's data scientist. He came on board in February of this year after stints at Harvard (working on climate science models), Washington Mutual, JP Morgan and Fannie Mae (analyzing mortgage securities) and more (including some research into Google Places rankings last November). Matt's particularly passionate about bringing the best practices of scientific and quantitative analysis to the world of inbound marketing, and I'm very excited to welcome him to the Moz community.
One of the most interesting findings from our 2011 Ranking Factors analysis was the high correlation between Facebook shares and Google US search position. In fact, Facebook shares was the highest correlated single factor among the 100+ factors we examined:
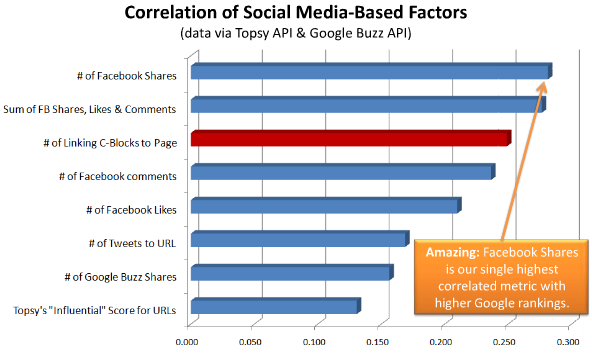
This blog post presents some modeling results that look at whether Google may be using Facebook shares directly in it's relevance calculation, or whether the correlation between Facebook shares and search position is coincidental, aka the byproduct of other causal factors.
Correlation and Causation
As we have said time and time again on this blog, in our presentations and when speaking, correlation is not causation. However, this post will discuss issues of both correlation and causation, so for the purposes of this discussion it's important to understand the relationship between them on a deeper level. Correlation does not, in general, imply causation. However, two things that are causally related will often be well correlated. Correlation can therefore only be used to support or deny causation, but not to show it directly. Put another way, if we have some prior, a priori, reason to believe that two things are related, correlation can be used as a tool (with rigorous statistical underpinnings) to support the relationship. In turn, weak correlation can be used to weaken the argument that two things are related.
Before we started our work on the 2011 Ranking Factors, we had some reasons to believe that Facebook data may be used by Google. There was an interview with Google/Bing in December 2010 where they disclosed that they were using social media signals in to rank search results. We also began seeing Facebook share information in our search results, so we knew that Google had access to at least some Facebook data.
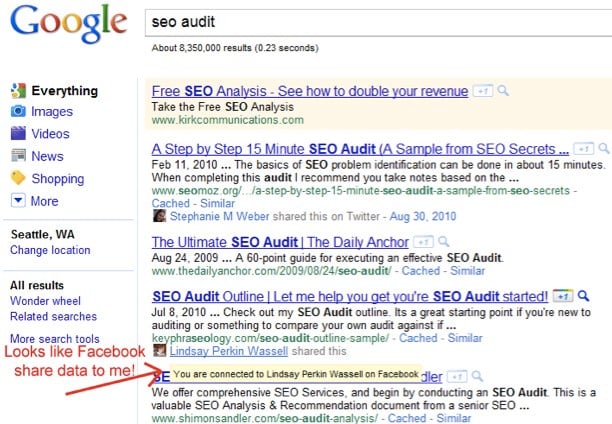
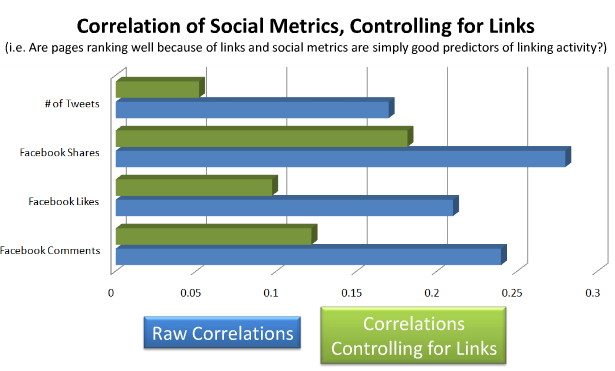
Even having this public comment from Google and seeing the Facebook data in search results (you can also observe them in Google realtime, e.g. here), we were still surprised at the size of the correlation in our ranking factor result and we wondered whether it was causal or the result of other factors like links. As a simple check, we ran some hasty partial correlations to control for links and concluded that they accounted for some of the correlation, but not all. This appeared to be another data point to support causation, or so we thought...
SMX Advanced
At SMX Advanced in Seattle last week, Rand Fishkin presented the main results from the ranking factors work, including the partial correlations controlling for links. We were still not confident that Facebook shares were being used directly, so Rand was very careful to add several caveats saying that these might not be causally related. You can see his presentation embedded below:
That evening, Matt Cutts, the head of Google's web spam team said that they do not crawl Facebook "wall" pages and implied that they don't use Facebook shares for ranking. His language was somewhat vague (leaving room open as to whether some forms of Facebook data are used or come via a special feed), however we and many others felt that Matt had implied that Facebook shares, specifically, are not part of their web ranking algorithm. Rand pointed out that Google does have some access to Facebook data overall and set up a small-scale test to determine if Google would index content that was solely shared on Facebook. To date, that page has not been indexed, despite having quite a few shares (64 according to the OpenGraph).
Both Rand and Matt's talks and the subsequent discussion with Danny Sullivan on Twitter was well covered over at Search Engine Land.
Sitting in the audience, I began to think about the implications of this new information. If Google wasn't using Facebook shares, then the high correlation must be explainable with things that they are using. I made a short list of different factors that Google might be using to determine relevance that would also be correlated with FB shares:
- Links. Pages that are heavily shared on Facebook tend to also be heavily linked to.
- Other social media signals. Pages that are shared on Facebook also tend to be tweeted about and shared through Google Buzz.
- Quality content. People share pages that they find interesting and have high quality content. This drives positive usage signals (time spent on page, bounce rate, etc) that might be used.
- Association with well known, quality brands. There is likely more interaction with well known brands then lesser known brands, and this might drive deeper engagement with them on Facebook.
Building a better model for Facebook shares
I thought back to the partial correlations I had run a few months prior. At the time, I was mainly interested in a first look that could be done in a few hours, so I chose partial correlations using a limited set of four metrics from Linkscape as the control variables. Partial correlations use a linear regression model to predict the correlation variables (in this case Facebook shares and search position), the simplest type of regression model. It has the benefit be being well established and easy to use, but falls short when the underlying relationship is more complicated or non-linear. In addition, I didn't try to control for other social media signals since at the time we were interested in links.
I began to wonder if the results would change if I tried a more complicated model using Twitter/Google Buzz and all the available link metrics from Linkscape so I set out to build the model. Before describing the model, it's important to write down our modeling assumptions. They are:
- Google uses link metrics for ranking, similar to those available in our Linkscape API.
- Google uses other social media data, in particular Tweets and Google Buzz shares to rank.
We are testing whether Facebook shares provide any increase in predictive power beyond these factors.
To build the model, I took a subset of the full dataset used in the ranking factors report (scrubbed for data quality, but otherwise unchanged). The baseline mean Spearman correlation between search position and Facebook shares in this data is 0.30. Then I took all 61 keyword agnostic link metrics used in the ranking factors and (1) ran them through a generic filter to transform them to something close to Gaussian and (2) did a principal component analysis and kept the first 19 principal components that explain 99% of the variability in the original data. This allows me to use a complicated non-linear model without worrying about collinearity issues. I augmented the 19 principal components with three social media metrics, namely the number of Tweets and Topsy Influential metrics from Topsy and the number of Google Buzz shares.
I used a two step process to fit the actual model. First, about 33% of the URLs don't have any Facebook shares and the rest have at least one share. Fitting a regression model to a distribution with a big spike at 0 is generally not a good idea, so I first fit a binary classifier to the cases for 0 / 1 or more shares. Then, I fit a non-linear regression model to the remaining data with at least one share. Over fitting was controlled through cross-validation. The total predicted number of shares can be computed from the output of these two pieces.
The final model performs moderately well, with the correlation coefficient between actual and predicted shares at 0.73. However, the mean Spearman correlation between the predicted number of shares and search position is 0.27, nearly as large as the baseline 0.30. This strongly suggests that our interpretation of Matt Cutts' statement is correct and Google is not using Facebook share data directly to rank.
Takeaways
- Facebook shares, at least as related to Google searches, act as a sort of "super-metric", encompassing a variety of different factors (similar to SEOmoz's Page Authority and Domain Authority).
- Don't stop sharing and generating brand engagement through Facebook! Driving deeper engagement through social media can only help your brand and likely has other positive benefits (by generating tweets or links, for example).
- Earning Facebook shares (probably) will not directly boost your Google rankings (though it may have positive effects that indirectly promote links, tweets and other signals Google may use).
- The process of doing this type of correlation work and sharing the results openly started a great dialogue in the search community, and through that we all learned more about how search works. We plan to do more work like this, and are planning a project for the Fall to compare Google and Bing results.
Finally, I'd like to thank Danny Sullivan and Matt Cutts for sparking this work through their discussion at SMX Advanced.
The author's views are entirely their own (excluding the unlikely event of hypnosis) and may not always reflect the views of Moz.


{kind=link}
Comments
Please keep your comments TAGFEE by following the community etiquette
Comments are closed. Got a burning question? Head to our Q&A section to start a new conversation.