

Headsmacking Tip #13: Don't Accidentally Block Link Juice with Robots.txt
A very simple return to the headsmacking series this week (as it's late here in London and I've been up my usual 40+ hours traveling).
We've been noticing that a number of websites seeking to block bot access to pages on their domain have been employing robots.txt to do so. While this is certainly a fine practice, the questions we've been getting show that there are a few misunderstandings about what blocking Google/Yahoo!/MSN/other search bots with robots.txt does. Here's a quick breakdown:
- Block with Robots.txt - do not attempt to visit the URL, but feel free to keep it in the index & display in the SERPs (see below if this confuses you)
- Block with Meta NoIndex - feel free to visit, but don't put the URL in the index or display in the results
- Block by Nofollowing Links - not a smart move, as other followed links can still put them in the index (it's fine if you don't want to "waste juice" on the page, but don't think it will keep bots away or prevent it from appearing in the SERPs)
Here's a quick example of a page that's blocked via robots.txt but appears in Google's index:
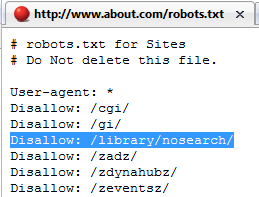
(note that this robots.txt is the same across about.com's other subdomains, too)
You can see that about.com is clearly disallowing the /library/nosearch/ folder. Yet, here's what happens when we search Google for URLs in that folder:
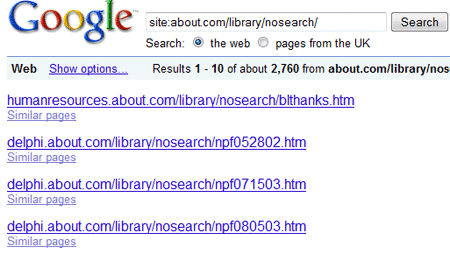
Notice that Google has 2,760 pages from that "disallowed" directory. They haven't crawled these URLs, so they appear as mere address strings (no title, description, etc - since Google can't see the pages' content).
Now think one step further - if you've got any number of pages you're blocking from the search engines' eyes, those URLs can still accumulate links, accumulate juice and other query-independent ranking factors, but they have no way to "pass it along" since their own links out will never be seen. I'll illustrate the situation:
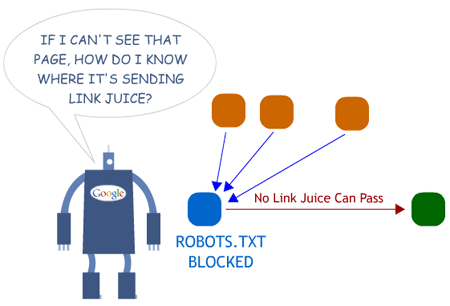
There's two real takeaways here:
- Conserve link juice by using nofollow when linking to a URL that is robots.txt disallowed
- If you know that disallowed pages have acquired link juice (particularly from external links), consider using meta noindex, follow instead so they can pass their link juice on to places on your site that need it.
Looking forward to seeing folks at SMX London tomorrow (and for Will and my big showdown on Tuesday, too)!
p.s. Andy Beard covered this topic previously in a solid post - SEO Linking Gotchas Even the Pros Make.
The author's views are entirely their own (excluding the unlikely event of hypnosis) and may not always reflect the views of Moz.


Comments
Please keep your comments TAGFEE by following the community etiquette
Comments are closed. Got a burning question? Head to our Q&A section to start a new conversation.