

How Big Was Penguin 3.0?
Sometime in the last week, the first Penguin update in over a year began to roll out (Penguin 2.1 hit around October 4, 2013). After a year, emotions were high, and expectations were higher. So, naturally, people were confused when MozCast showed the following data:

The purple bar is Friday, October 17th, the day Google originally said Penguin 3.0 rolled out. Keep in mind that MozCast is tuned to an average temperature of roughly 70°F. Friday’s temperature was slightly above average (73.6°), but nothing in the last few days indicates a change on the scale of the original Penguin update. For reference, Penguin 1.0 measured a scorching 93°F.
So, what happened? I’m going to attempt to answer that question as honestly as possible. Fair warning – this post is going to dive very deep into the MozCast data. I’m going to start with the broad strokes, and paint the finer details as I go, so that anyone with a casual interest in Penguin can quit when they’ve seen enough of the picture.
What’s in a name?
We think that naming something gives us power over it, but I suspect the enchantment works both ways – the name imbues the update with a certain power. When Google or the community names an algorithm update, we naturally assume that update is a large one. What I’ve seen across many updates, such as the 27 named Panda iterations to date, is that this simply isn’t the case. Panda and Penguin are classifiers, not indicators of scope. Some updates are large, and some are small – updates that share a name share a common ideology and code-base, but they aren’t all equal.
Versioning complicates things even more – if Barry Schwartz or Danny Sullivan name the latest update “3.0”, it’s mostly a reflection that we’ve waited a year and we all assume this is a major update. That feels reasonable to most of us. That doesn’t necessarily mean that this is an entirely new version of the algorithm. When a software company creates a new version, they know exactly what changed. When Google refreshes Panda or Penguin, we can only guess at how the code changed. Collectively, we do our best, but we shouldn’t read too much into the name.
Was this Penguin just small?
Another problem with Penguin 3.0 is that our expectations are incredibly high. We assume that, after waiting more than a year, the latest Penguin update will hit hard and will include both a data refresh and an algorithm update. That’s just an assumption, though. I firmly believe that Penguin 1.0 had a much broader, and possibly much more negative, impact on SERPs than Google believed it would, and I think they’ve genuinely struggled to fix and update the Penguin algorithm effectively.
My beliefs aside, Pierre Far tried to clarify Penguin 3.0’s impact on Oct 21, saying that it affected less than 1% of US/English queries, and that it is a “slow, worldwide rollout”. Interpreting Google’s definition of “percent of queries” is tough, but the original Penguin (1.0) was clocked by Google as impacting 3.1% of US/English queries. Pierre also implied that Penguin 3.0 was a data “refresh”, and possibly not an algorithm change, but, as always, his precise meaning is open to interpretation.
So, it’s possible that the graph above is correct, and either the impact was relatively small, or that impact has been spread out across many days (we’ll discuss that later). Of course, many reputable people and agencies are reporting Penguin hits and recoveries, so that begs the question – why doesn’t their data match ours?
Is the data just too noisy?
MozCast has shown me with alarming clarity exactly how messy search results can be, and how dynamic they are even without major algorithm updates. Separating the signal from the noise can be extremely difficult – many SERPs change every day, sometimes multiple times per day.
More and more, we see algorithm updates where a small set of sites are hit hard, but the impact over a larger data set is tough to detect. Consider the following two hypothetical situations:

The data points on the left have an average temperature of 70°, with one data point skyrocketing to 110°. The data points on the right have an average temperature of 80°, and all of them vary between about 75-85°. So, which one is the update? A tool like MozCast looks at the aggregate data, and would say it’s the one on the right. On average, the temperature was hotter. It’s possible, though, that the graph on the left represents a legitimate update that impacted just a few sites, but hit those sites hard.
Your truth is your truth. If you were the red bar on the left, then that change to you is more real than any number I can put on a graph. If the unemployment rate drops from 6% to 5%, the reality for you is still either that you have a job or don’t have a job. Averages are useful for understanding the big picture, but they break down when you try to apply them to any one individual case.
The purpose of a tool like MozCast, in my opinion, is to answer the question “Was it just me?” We’re not trying to tell you if you were hit by an update – we’re trying to help you determine if, when you are hit, you’re the exception or the rule.
Is the slow rollout adding noise?
MozCast is built around a 24-hour cycle – it is designed to detect day-over-day changes. What if an algorithm update rolls out over a couple of days, though, or even a week? Is it possible that a relatively large change could be spread thin enough to be undetectable? Yes, it’s definitely possible, and we believe Google is doing this more often. To be fair, I don’t believe their primary goal is to obfuscate updates – I suspect that gradual rollouts are just safer and allow more time to address problems if and when things go wrong.
While MozCast measures in 24-hour increments, the reality is that there’s nothing about the system limiting it to that time period. We can just as easily look at the rate of change over a multi-day window. First, let’s stretch the MozCast temperature graph from the beginning of this post out to 60 days:

For reference, the average temperature for this time period was 68.5°. Please note that I’ve artificially constrained the temperature axis from 50-100° – this will help with comparisons over the next couple of graphs. Now, let’s measure the “daily” temperature again, but this time we’ll do it over a 48-hour (2-day) period. The red line shows the 48-hour flux:

It’s important to note that 48-hour flux is naturally higher than 24-hour flux – the average of the 48-hour flux for these 60 days is 80.3°. In general, though, you’ll see that the pattern of flux is similar. A longer window tends to create a smoothing effect, but the peaks and valleys are roughly similar for the two lines. So, let’s look at 72-hour (3-day) flux:

The average 72-hour flux is 87.7° over the 60 days. Again, except for some smoothing, there’s not a huge difference in the peaks and valleys – at least nothing that would clearly indicate the past week has been dramatically different from the past 60 days. So, let’s take this all the way and look at a full 7-day flux calculation:

I had to bump the Y-axis up to 120°, and you’ll see that smoothing is in full force – making the window any larger is probably going to risk over-smoothing. While the peaks and valleys start to time-shift a bit here, we’re still not seeing any obvious climb during the presumed Penguin 3.0 timeline.
Could Penguin 3.0 be spread out over weeks or a month? Theoretically, it’s possible, but I think it’s unlikely given what we know from past Google updates. Practically, this would make anything but a massive update very difficult to detect. Too much can change in 30 days, and that base rate of change, plus whatever smaller updates Google launched, would probably dwarf Penguin.
What if our keywords are wrong?
Is it possible that we’re not seeing Penguin in action because of sampling error? In other words, what if we’re just tracking the wrong keywords? This is a surprisingly tough question to answer, because we don’t know what the population of all searches looks like. We know what the population of Earth looks like – we can’t ask seven billion people to take our survey or participate in our experiment, but we at least know the group that we’re sampling. With queries, only Google has that data.
The original MozCast was publicly launched with a fixed set of 1,000 keywords sampled from Google AdWords data. We felt that a fixed data set would help reduce day-over-day change (unlike using customer keywords, which could be added and deleted), and we tried to select a range of phrases by volume and length. Ultimately, that data set did skew a bit toward commercial terms and tended to contain more head and mid-tail terms than very long-tail terms.
Since then, MozCast has grown to what is essentially 11 weather stations of 1,000 different keywords each, split into two sets for analysis of 1K and 10K keywords. The 10K set is further split in half, with 5K keywords targeted to the US (delocalized) and 5K targeted to 5 cities. While the public temperature still usually comes from the 1K set, we use the 10K set to power the Feature Graph and as a consistency check and analysis tool. So, at any given time, we have multiple samples to compare.
So, how did the 10K data set (actually, 5K delocalized keywords, since local searches tend to have more flux) compare to the 1K data set? Here’s the 60-day graph:

While there are some differences in the two data sets, you can see that they generally move together, share most of the same peaks and valleys, and vary within roughly the same range. Neither set shows clear signs of large-scale flux during the Penguin 3.0 timeline.
Naturally, there are going to be individual SEOs and agencies that are more likely to track clients impacted by Penguin (who are more likely to seek SEO help, presumably). Even self-service SEO tools have a certain degree of self-selection – people with SEO needs and issues are more likely to use them and to select problem keywords for tracking. So, it’s entirely possible that someone else’s data set could show a more pronounced Penguin impact. Are they wrong or are we? I think it’s fair to say that these are just multiple points of view. We do our best to make our sample somewhat random, but it’s still a sample and it is a small and imperfect representation of the entire world of Google.
Did Penguin 3.0 target a niche?
In that every algorithm update only targets a select set of sites, pages, or queries, then yes – every update is a "niche" update. The only question we can pose to our data is whether Penguin 3.0 targeted a specific industry category/vertical. The 10K MozCast data set is split evenly into 20 industry categories. Here's the data from October 17th, the supposed data of the main rollout:

Keep in mind that, split 20 ways, the category data for any given day is a pretty small set. Also, categories naturally stray a bit from the overall average. All of the 20 categories recorded temperatures between 61.7-78.2°. The "Internet & Telecom" category, at the top of the one-day readings, usually runs a bit above average, so it's tough to say, given the small data set, if this temperature is meaningful. My gut feeling is that we're not seeing a clear, single-industry focus for the latest Penguin update. That's not to say that the impact didn't ultimately hit some industries harder than others.
What if our metrics are wrong?
If the sample is fundamentally flawed, then the way we measure our data may not matter that much, but let’s assume that our sample is at least a reasonable window into Google’s world. Even with a representative sample, there are many, many ways to measure flux, and all of them have pros and cons.
MozCast still operates on a relatively simple metric, which essentially looks at how much the top 10 rankings on any given day change compared to the previous day. This metric is position- and direction-agnostic, which is to say that a move from #1 to #3 is the same as a move from #9 to #7 (they’re both +2). Any keyword that drops off the rankings is a +10 (regardless of position), and any given keyword can score a change from 0-100. This metric, which I call “Delta100”, is roughly linearly transformed by taking the square root, resulting in a metric called “Delta10”. That value is then multiplied by a constant based on an average temperature of 70°. The transformations involve a little more math, but the core metric is pretty simplistic.
This simplicity may lead people to believe that we haven’t developed more sophisticated approaches. The reality is that we’ve tried many metrics, and they tend to all produce similar temperature patterns over time. So, in the end, we’ve kept it simple.
For the sake of this analysis, though, I’m going to dig into a couple of those other metrics. One metric that we calculate across the 10K keyword set uses a scoring system based on a simple CTR curve. A change from, say #1 to #3 has a much higher impact than a change lower in the top 10, and, similarly, a drop from the top of page one has a higher impact than a drop from the bottom. This metric (which I call “DeltaX”) goes a step farther, though…
If you’re still riding this train and you have any math phobia at all, this may be the time to disembark. We’ll pause to make a brief stop at the station to let you off. Grab your luggage, and we’ll even give you a couple of drink vouchers – no hard feelings.
If you’re still on board, here’s where the ride gets bumpy. So far, all of our metrics are based on taking the average (mean) temperature across the set of SERPs in question (whether 1K or 10K). The problem is that, as familiar as we all are with averages, they generally rely on certain assumptions, including data that is roughly normally distributed.
Core flux, for lack of a better word, is not remotely normally distributed. Our main Delta100 metric falls roughly on an exponential curve. Here’s the 1K data for October 21st:

The 10K data looks smoother, and the DeltaX data is smoother yet, but the shape is the same. A few SERPs/keywords show high flux, they quickly drop into mid-range flux, and then it all levels out. So, how do we take an average of this? Put simply, we cheat. We tested a number of transformations and found that the square root of this value helped create something a bit closer to a normal distribution. That value (Delta10) looks like this:

If you have any idea what a normal distribution is supposed to look like, you’re getting pretty itchy right about now. As I said, it’s a cheat. It’s the best cheat we’ve found without resorting to some really hairy math or entirely redefining the mean based on an exponential function. This cheat is based on an established methodology – Box-Cox transformations – but the outcome is admittedly not ideal. We use it because, all else being equal, it works about as well as other, more complicated solutions. The square root also handily reduces our data to a range of 0-10, which nicely matches a 10-result SERP (let’s not talk about 7-result SERPs… I SAID I DON’T WANT TO TALK ABOUT IT!).
What about the variance? Could we see how the standard deviation changes from day-to-day instead? This gets a little strange, because we’re essentially looking for the variance of the variance. Also, noting the transformed curve above, the standard deviation is pretty unreliable for our methodology – the variance on any given day is very high. Still, let’s look at it, transformed to the same temperature scale as the mean/average (on the 1K data set):

While the variance definitely moves along a different pattern than the mean, it moves within a much smaller range. This pattern doesn’t seem to match the pattern of known updates well. In theory, I think tracking the variance could be interesting. In practice, we need a measure of variance that’s based on an exponential function and not our transformed data. Unfortunately, such a metric is computationally expensive and would be very hard to explain to people.
Do we have to use mean-based statistics at all? When I experimented with different approaches to DeltaX, I tried using a median-based approach. It turns out that the median flux for any given day is occasionally zero, so that didn’t work very well, but there’s no reason – at least in theory – that the median has to be measured at the 50th percentile.
This is where you’re probably thinking “No, that’s *exactly* what the median has to measure – that’s the very definition of the median!” Ok, you got me, but this definition only matters if you’re measuring central tendency. We don’t actually care what the middle value is for any given day. What we want is a metric that will allow us to best distinguish differences across days. So, I experimented with measuring a modified median at the 75th percentile (I call it “M75” – you’ve probably noticed I enjoy codenames) across the more sophisticated DeltaX metric.
That probably didn’t make a lot of sense. Even in my head, it’s a bit fuzzy. So, let’s look at the full DeltaX data for October 21st:

The larger data set and more sophisticated metric makes for a smoother curve, and a much clearer exponential function. Since you probably can’t see the 1,250th data point from the left, I’ve labelled the M75. This is a fairly arbitrary point, but we’re looking for a place where the curve isn’t too steep or too shallow, as a marker to potentially tell this curve apart from the curves measured on other days.
So, if we take all of the DeltaX-based M75’s from the 10K data set over the last 60 days, what does that look like, and how does it compare to the mean/average of Delta10s for that same time period?
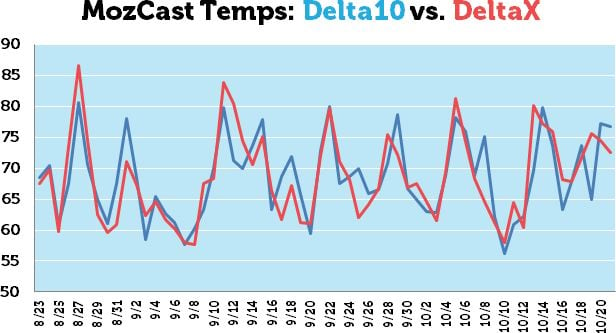
Perhaps now you feel my pain. All of that glorious math and even a few trips to the edge of sanity and back, and my wonderfully complicated metric looks just about the same as the average of the simple metric. Some of the peaks are a bit peakier and some a bit less peakish, but the pattern is very similar. There’s still no clear sign of a Penguin 3.0 spike.
Are you still here?
Dear God, why? I mean, seriously, don’t you people have jobs, or at least a hobby? I hope now you understand the complexity of the task. Nothing in our data suggests that Penguin 3.0 was a major update, but our data is just one window on the world. If you were hit by Penguin 3.0 (or if you received good news and recovered) then nothing I can say matters, and it shouldn’t. MozCast is a reference point to use when you’re trying to figure out whether the whole world felt an earthquake or there was just construction outside your window.



Comments
Please keep your comments TAGFEE by following the community etiquette
Comments are closed. Got a burning question? Head to our Q&A section to start a new conversation.