

Knowledge Graph 2.0: Now Featuring Your Knowledge
Sometime in January, Google quietly rolled out a change that I believe could revolutionize organic search. Currently, the impact is limited, and it may take months or years for the full effect to be felt, but the underlying shift is fundamental to the future of the Knowledge Graph and the delicate symbiosis between Google and webmasters.
Answer box 1.0
Let's start at the beginning. I've written a lot about the current generation of answer boxes (sometimes called "direct answers" or "one-box answers"). These display quick answers to what are usually concrete questions. For example, if I want to know when the Willis Tower here in Chicago is open, I can search for [Willis tower hours] and get:

Google's ability to understand questions has expanded significantly in the past couple of years, probably pushed forward even more by the Hummingbird update. For example, I can get the same answer box by querying [when is the Sears Tower open].
So, where is this data coming from? Typically, it's coming directly from the Knowledge Graph, and you can spot it pretty easily. Here's the Knowledge Panel for [Willis tower]:
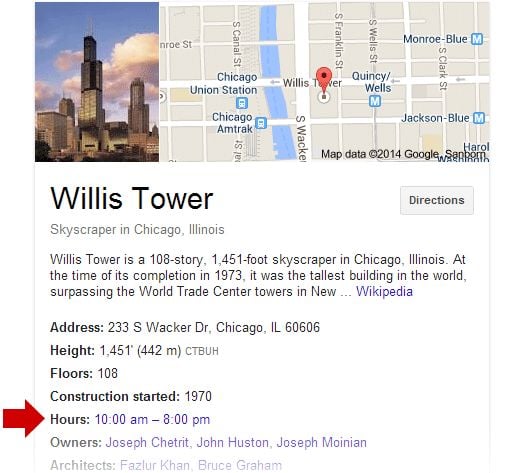
I've added the red arrow – as you can see, the information in the answer box is taken directly from a property in the Knowledge Graph. You can easily reverse it, too, to create endless examples. Let's take the property "Construction started: 1970" and turn it into a query, like [when was the sears tower built]. You'll get another answer box:

Most of this information comes from a very limited number of sources, including Freebase, Wikipedia, and Google+. Freebase is structured in terms of entities and properties (think object-based, as opposed to article-based), which makes it a perfect fit for Knowledge Graph.
Google's dilemma
There's a problem, though. The main sources of data for the Knowledge Graph are curated by people. Ironically, Google is facing the same dilemma with Knowledge Graph in 2014 that led to the creation of internet search engines in the first place. Put simply, the scope of information is much too large, and growing too quickly, for any human-edited approach to scale. Google can't just hire Wikipedia editors – they need a new data source.
Google is hardly blind to this problem. In a research paper published just this year, Google outlines the basic issue (hat-tip to Andrew Isidoro):

The paper goes on to explain a method of extracting missing knowledge graph data on demand, using Google's existing search technology. Welcome to...
Answer box 2.0
Luckily (for them), Google already has one of the largest data sources on the planet – their index of the worldwide web. What if, instead of looking for answers in a limited set of encyclopedic sources, Google could generate answers directly from our websites?
That's exactly what they've done. For example, here's what you'll see at the top of a recent search for [social security tax rate]:

Unlike answer boxes based on the Knowledge Graph, this new format pulls its answer directly from third party websites, giving them attribution via the page title and link. In many ways, this is an additional organic result, and like all answer boxes in the left-hand column, it appears above "#1".
These longer answers look more like search snippets, but there's also a second version, triggered when Google can find a definitive answer on a third-party site. Here's the new answer box for the query [September birthstone]:

This example includes a longer snippet, but the direct answer – "Sapphire" – is highlighted, more in the style of a traditional answer box. Again, the source page's title and URL is shown below the snippet.
How do we know, beyond the third-party attribution, that this isn't coming from the traditional Knowledge Graph? Try a variation on the query, like [september's birthstone]. I get this result:

Here's the answer box for a longer query [what is september's birthstone]:

Interestingly, the short answer ("sapphire") is no longer capitalized, because that's how Google found it on the source page. In my personal testing, these variations weren't consistent, so Google may be using some kind of query refinement. Regardless of that, it's pretty clear that these answers are being generated on the fly.
The new number one
These answer boxes are essentially a new organic result, and clearly disrupt the traditional top results. So, where are these answers coming from, and how do you get one? We don't have a lot of data yet, but in every case I've seen, the URL used to create the answer box also appears on page one of Google results. So, you have to already be ranking well on the term.
In most of the cases that I've seen so far (again, the data set is small), the answer is coming from the #1 organic position. For example, here's the answer box and #1 result I get for [marine corps' birthday]:

So, military.com is essentially getting two listings on this SERP. In some cases, though, the answer is coming from a result lower on page 1. Here's the answer box and part of page 1 for [richest man in the world]:

In this case, Time Magazine gets credit for the answer box, even though it's all the way down in #8, and Forbes has all three of the top organic spots. What's even worse is that Time article directly cites Forbes as the source, even in the search snippet. So, what's going on here?
I suspect this comes down to fairly basic on-page factors. The main Forbes article is a bit design-heavy (it has limited crawlable text) and uses an "infinite" scroll approach. None of the Forbes pages directly mention the phrase "richest man in the world", especially in proximity to Bill Gates' name.
What if I change my query to something that Forbes targets better, like [world's richest people]? Here's the result I get (all of these searches are incognito, but I can't rule out some sort of query history effect):

It's interesting that Google seems to be inferring that I want to know the world's richest person (and is bolding "Bill Gates"), but doesn't feel that the answer is definitive enough to break it out as a short answer. Even since starting this post, Google has made refinements to the matching system, but currently it seems like on-page keyword targeting is fairly critical.
It's just the beginning
Google clearly has a long way to go. Some of the answer boxes are pretty ridiculous. Take, for example, a search for [hair color]:

This is a pretty ambiguous query, and it doesn't seem well suited for any kind of answer box (let alone one that's one step away from a salon advertisement). Expect Google to put a lot of time and money into improving this system over the next year.
While this post is focused on answer boxes, Google is using a similar approach to expand knowledge panels. For example, here's a search for [biology]:

Notice the "Related topics" section – only one of those results is coming from Wikipedia. Google is building a decent chunk of this knowledge panel on sites in their index. The attribution on these is much more subtle – only the small, gray text goes to the source site. The blue links (except for "Wikipedia" at the top) go directly to more Google searches.
Is the balance shifting?
It's easy to see how this progression is inevitable – Google has to expand the Knowledge Graph, and they can't rely on human editors and static data sources. While this data may be good for users, it represents a shift in the balance between Google and webmasters. There's always been an implied symbiosis – Google crawls our sites and extracts information, but they send us traffic in return. We may not always like how they do things, but the end result has benefitted millions of site owners.
What happens when a user can get a simple answer quickly, and that answer is extracted from a third party page and cannibalizes the organic clicks? What happens when third-party data is being used not to drive traffic to the source, but to more Google searches? It seems to me that the symbiosis is threatened.
For now, there's not much you can do. You can work to retune your on-page content to appear in these new entities, but you do so at the risk of harming your own organic traffic. It's probably better to be in the answer box than let your competitor be there, but it's hardly an ideal choice. The best I can say is to be aware of your money terms – not just how you're ranking, but how those SERPs actually look in context. At some point, we may all have to decide if giving away our data is worth what we get in return.



Comments
Please keep your comments TAGFEE by following the community etiquette
Comments are closed. Got a burning question? Head to our Q&A section to start a new conversation.