

Logic, Meet Google - Crawling to De-index
Since the Panda update, more and more people are trying to control their Google index and prune out low-quality pages. I’m a firm believer in aggressively managing your own index, but it’s not always easy, and I’m seeing a couple of common mistakes pop up. One mistake is thinking that to de-index a page, you should block the crawl paths. Makes sense, right? If you don’t want a page indexed, why would you want it crawled? Unfortunately, while it sounds logical, it’s also completely wrong. Let’s look at an example…
Scenario: Product Reviews
Let’s pretend we have a decent-sized e-commerce site with 1,000 unique product pages. Those pages look something like this:

Each product page has its own URL, of course, and those URLs are structured as follows:
- http://www.example.com/product/1
- http://www.example.com/product/2
- http://www.example.com/product/3
- http://www.example.com/product/1000
Now let’s say that each of these product pages links to a review page for that product:
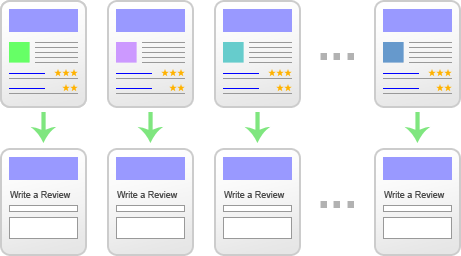
These review pages also have their own, unique URLs (tied to the product ID), like so:
- http://www.example.com/review/1
- http://www.example.com/review/2
- http://www.example.com/review/3
- http://www.example.com/review/1000
Unfortunately, we’ve just spun out 1,000 duplicate pages, as every review page is really only a form and has no unique content. Those review pages have no search value and are just diluting our index. So, we decide it’s time to take action…
The “Fix”, Part 1
We want these pages gone, so we decide to use the META NOINDEX (Meta Robots) tag. Since we really, really want the pages out completely, we also decide to nofollow the review links. Our first attempt at a fix ends up looking something like this:
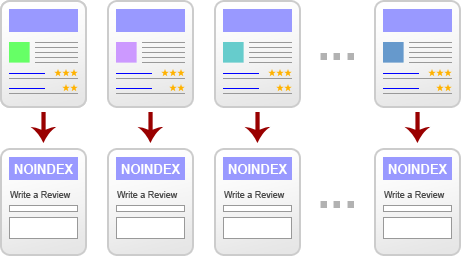
On the surface, it makes sense. Here’s the problem, though – those red arrows are now cut paths, potentially blocking the spiders. If the spiders never go back to the review pages, they’ll never read the NOINDEX and they won’t de-index the pages. Best case, it’ll take a lot longer (and de-indexation already takes too long on large sites).
The Fix, Part 2
Instead, let’s leave the path open (let the link be followed). That way, crawlers will continue to visit the pages, and the duplicate review URLs should gradually disappear:
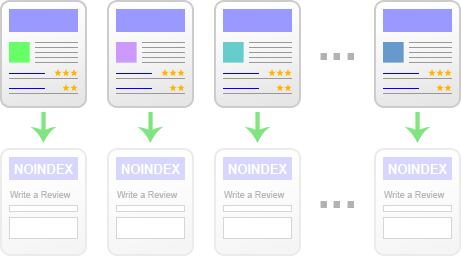
Keep in mind, this process can still take a while (weeks, in most cases). Monitor your index (with the “site:” operator) daily – you’re looking for a gradual decrease over time. If that’s happening, you’re in good shape. Pro tip: Don’t take any single day’s “site:” count too seriously – it can be unreliable from time to time. Look at the trend over time.
New vs. Existing Sites
I think it’s important to note that this problem only applies to existing sites, where the duplicate URLs have already been indexed. If you’re launching a new site, then putting nofollows on the review links is perfectly reasonable. You may also want to put the nofollows in place down the road, after the bad URLs have been de-indexed. The key is not to do it right away – give the crawlers time to do their job.
301, Rel-canonical, etc.
Although my example used nofollow and META NOINDEX, it applies to any method of blocking an internal link (including outright removal) and any page-based or header-based indexation cue. That includes 301-redirects and canonical tags (rel-canonical). To process those signals, Google has to crawl the pages – if you cut the path before Google can re-crawl, then those signals are never going to do their job.
Don’t Get Ahead of Yourself
It’s natural to want to solve problems quickly (especially when you’re facing lost traffic and lost revenue), and indexation issues can be very frustrating, but plan well and give the process time. When you block crawl paths before de-indexation signals are processed or try to throw everything but the kitchen sink at a problem (NOINDEX + 301 + canonical + ?), you often create more problems than you solve. Pick the best tool for the job, and give it time to work.
Update: A couple of commenters pointed out that you can use XML sitemaps to encourage Google to recrawl pages with no internal links. That's a good point and one I honestly forgot to mention. While internal links are still more powerful, an XML sitemap with the nofollow'ed (or removed) URLs can help speed the process. This is especially effective when it's not possible to put the URLs back in place (a total redesign, for example).



Comments
Please keep your comments TAGFEE by following the community etiquette
Comments are closed. Got a burning question? Head to our Q&A section to start a new conversation.