
Featured Resources

The SEO's Guide to Content Marketing
Learn the ins and outs of content marketing along with how it can benefit your business.

Content Strategy Template
Start building a comprehensive content strategy.
Popular Articles

On-Page Ranking Factors
Learn what on-site signals impact rankings.

What Content Should I Create?
Learn about the different types of content you can create to engage your audience.

The Content Refresh: How to Do More With Less
Kameron Jenkins talks through how to make content go farther and rank faster with a content refresh strategy.

Counterintuitive Content: How New Trends Have Disrupted Years of Bad Advice
Casie Gillette introduces a different perspective to content marketing and how to produce content on your own terms.

Why Content Marketing?
In this episode of Whiteboard Friday, Rand Fishkin talks through why content marketing works and how it can help your business.

Creating Successful Content
In this episode of Whiteboard Friday, Cyrus Shepard discusses how to create successful content.
The Latest From The Blog
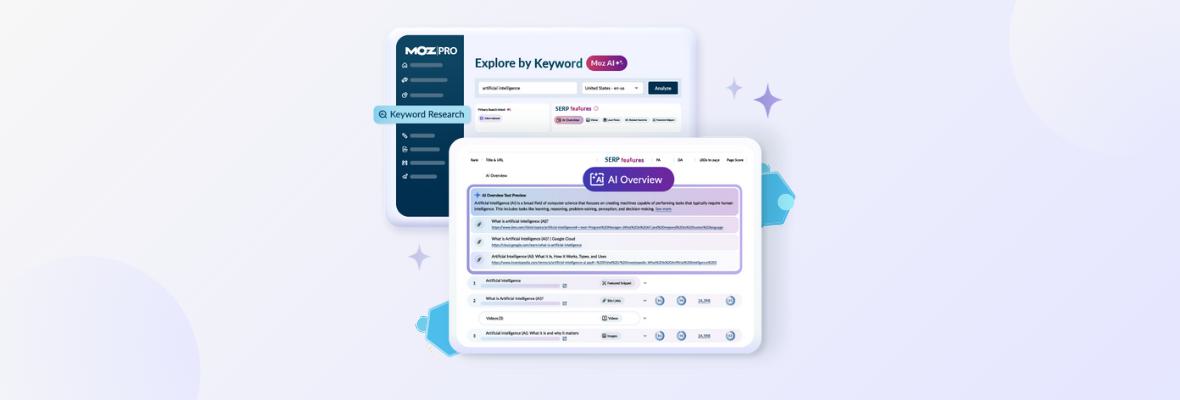
Are AI Overviews Worth Pursuing? — Next Level

Elevating Your SEO Career and Team in the AI Era — Whiteboard Friday

How To Adjust Your Content Strategy for Google’s AI Mode
Ready to learn more?
Watch the most recent MozCon talks to gain even more insight into successful content marketing.