
Building a Better Spam Detector
A couple of weeks ago the AIRWeb held its 2008 conference. After seeing Dr. Garcia's post on the conference I was going read the papers and provide a high-level overview of some of the papers. However, after I saw that they were holding a web spam competition, my interests headed in a different direction. At the risk of raising Dr. Garcia's ire (a mistake I've made in the past), I have, with tongue placed throughly in cheek, developed my own spam detection algorithm. And that algorithm has performed surprisingly well!
I turned my project into a tool you can use to check if a domain name looks spammy. I'm not making any guarantees with it though. It could be a nifty tool if you want to have a high-quality domain name. Or at least, one which is not obviously spammy:
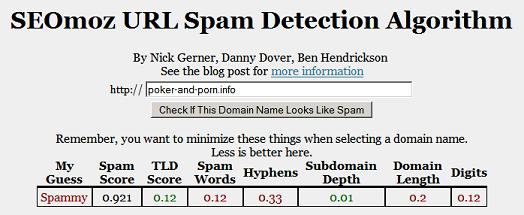
UPDATE: There were a few bugs in the earlier version, I've fixed those (but not the other ones I don't know about yet), so now things should be (at least slightly) better!
You probably understand the basic idea of spam detection:
On the one hand you could label everything as non-spam and you would never have a false positive. This is the point on the graph where x=0 and y=0. On the other hand, you could just label everything as spam and no SERPs would contain any spam pages. Of course, there would be no pages in any SERP at all, and this whole industry would have to go to back-up plans. I'd be a roadie for my wife's Rock Band tours.
Here is a plot illustrating the trade-offs, as adapted by me from the AIRWeb 2008 conference, including my own fancy algorithm. "y=x" is the base-line random classifier (you better be smarter than this one!)
see the actual results
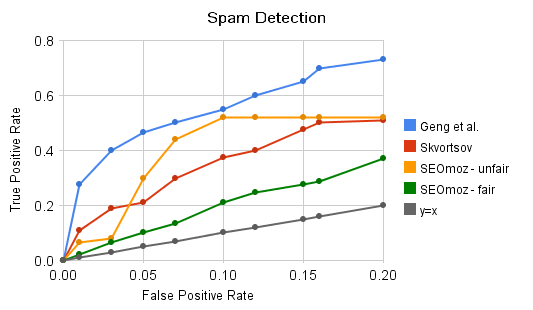
Clearly, the graph shows that I totally rocked :) Ignore for a minute the line labeled "SEOmoz - fair", we'll come back to this. As you can see, at a false positive rate of 10% (0.10), I was able to successfully label over 50% of the spam pages, outperforming the worst algorithm from the workshop (Skvortsov at ~39%), and performing nearly as well as the best (Geng, et al. at ~55%). My own algorithm, SpamDilettante® (patent pending!) , developed in just two days, with only the help of our very own totally amazing intern Danny Dover and secret dev weapon Ben Hendrickson has outperformed some of the best and brightest researchers in the field of adversarial information retrieval.
Well, graphs lie. And so do I. Let me explain what's going on here. First of all, my algorithm really does classify spam. And I really did develop it in just two days without using a link-graph, extracting complex custom web features, or racking up many days or months of compute cluster time. But there are some important caveats I'll get to, and these are illustrated by the much worse line called "fair" above.
What I did was begin with not one of Rand's most popular blog posts. However, this post is actually filled with excellent content (see the graph above). Most of the things I couldn't actually compute very easily:
However, some of the things I could get just from the domain name:
With the hard work done for me, I wrote a script to extract the above features (in just a few lines of python code). I took the 2/3 of the data which was labeled as spam/non-spam and divided it into an 80% "training set" and 20% "test set". This is important because if you can see the labels for all your data you might as well just hard-code what's spam and what's not. And then you win (remember that "perfect" algorithm?). Anyway, I just did a linear regression on this 80% set and got my classifier.
To get performance numbers I used my classifier on my reserved 20% test set. Basically it spewed a bunch of numbers like "0.87655" which you could think of as probabilities. To get the above curve, I tried a series of thresholds (e.g. IF prob > 0.7 THEN spam ELSE not spam). This is the trade-off between false positive and false negative, and gives me the above curves.
And that's the story of how I beat the academicians.
O.K., back to reality for a moment; on to the caveats.
As E. Garcia said in his original post which started me on this, "it is time to revisit [the] drawing board."
I turned my project into a tool you can use to check if a domain name looks spammy. I'm not making any guarantees with it though. It could be a nifty tool if you want to have a high-quality domain name. Or at least, one which is not obviously spammy:
UPDATE: There were a few bugs in the earlier version, I've fixed those (but not the other ones I don't know about yet), so now things should be (at least slightly) better!
You probably understand the basic idea of spam detection:
- The engines (and surfers) don't like the spam pages.
- Enter the PhD-types with their fancy models, support from the engines with their massive data-centers, funding for advanced research, and whole lot more smarts than I've got.
On the one hand you could label everything as non-spam and you would never have a false positive. This is the point on the graph where x=0 and y=0. On the other hand, you could just label everything as spam and no SERPs would contain any spam pages. Of course, there would be no pages in any SERP at all, and this whole industry would have to go to back-up plans. I'd be a roadie for my wife's Rock Band tours.
Here is a plot illustrating the trade-offs, as adapted by me from the AIRWeb 2008 conference, including my own fancy algorithm. "y=x" is the base-line random classifier (you better be smarter than this one!)
see the actual results
Clearly, the graph shows that I totally rocked :) Ignore for a minute the line labeled "SEOmoz - fair", we'll come back to this. As you can see, at a false positive rate of 10% (0.10), I was able to successfully label over 50% of the spam pages, outperforming the worst algorithm from the workshop (Skvortsov at ~39%), and performing nearly as well as the best (Geng, et al. at ~55%). My own algorithm, SpamDilettante® (patent pending!) , developed in just two days, with only the help of our very own totally amazing intern Danny Dover and secret dev weapon Ben Hendrickson has outperformed some of the best and brightest researchers in the field of adversarial information retrieval.
Well, graphs lie. And so do I. Let me explain what's going on here. First of all, my algorithm really does classify spam. And I really did develop it in just two days without using a link-graph, extracting complex custom web features, or racking up many days or months of compute cluster time. But there are some important caveats I'll get to, and these are illustrated by the much worse line called "fair" above.
What I did was begin with not one of Rand's most popular blog posts. However, this post is actually filled with excellent content (see the graph above). Most of the things I couldn't actually compute very easily:
- High ratio of ad blocks to content
- Small amounts of unique content
- Very few direct visits
- Less likely to have links from trusted sources
- Unlikely to register with Google/Yahoo!/MSN Local Services
- Many levels of links away from highly trusted websites
- Cloaking based on user-agent or IP address is common
However, some of the things I could get just from the domain name:
- Long domain names
- .info, .cc, .us and other cheap, easy to grab TLDs
- Use of common, high-commercial value spam keywords in the domain name
- More likely to contain multiple hyphens in the domain name
- Less likely to have .com or .org extensions
- Almost never have .mil, .edu or .gov extensions
With the hard work done for me, I wrote a script to extract the above features (in just a few lines of python code). I took the 2/3 of the data which was labeled as spam/non-spam and divided it into an 80% "training set" and 20% "test set". This is important because if you can see the labels for all your data you might as well just hard-code what's spam and what's not. And then you win (remember that "perfect" algorithm?). Anyway, I just did a linear regression on this 80% set and got my classifier.
To get performance numbers I used my classifier on my reserved 20% test set. Basically it spewed a bunch of numbers like "0.87655" which you could think of as probabilities. To get the above curve, I tried a series of thresholds (e.g. IF prob > 0.7 THEN spam ELSE not spam). This is the trade-off between false positive and false negative, and gives me the above curves.
And that's the story of how I beat the academicians.
O.K., back to reality for a moment; on to the caveats.
- As I pointed out in the introduction to the competition my data set is a much simpler classification problem (complete label coverage and almost no class imbalance)
- As Rebecca says, "it's just one of those "common seo knowledge" things--.info, .biz, a lot of .net [are spam]," and my dataset includes lot of these "easy targets". The competition is all .uk (and mostly co.uk)
- My dataset is awfully small and likely has all kinds of sampling problems. My results probably do not generalize.
As E. Garcia said in his original post which started me on this, "it is time to revisit [the] drawing board."



Comments
Please keep your comments TAGFEE by following the community etiquette
Comments are closed. Got a burning question? Head to our Q&A section to start a new conversation.