
Linkscape Index Update and a Peek Behind the Curtains
Last week we updated the Linkscape index, and we've been doing it again this week. As I've pointed out in the past, up-to-date data is critical. So we're pushing everyone around here just about as hard as we can to provide that to you. This time we've got updated information on over 43 billion urls, 275 million sub-domains, 77 million root domains, and 445 billion links. For those keeping track, the next update should be around April 15.
I've got three important points in this post. So for your click-y enjoyment:
If you've been keeping track, you may have noticed a drop in pages and links in our index in the last two or three months. You'll notice that I call these graphs "Fresh Index Size", by which I mean that these numbers by and large reflect only what we verified in the prior month. So what happened to those links?
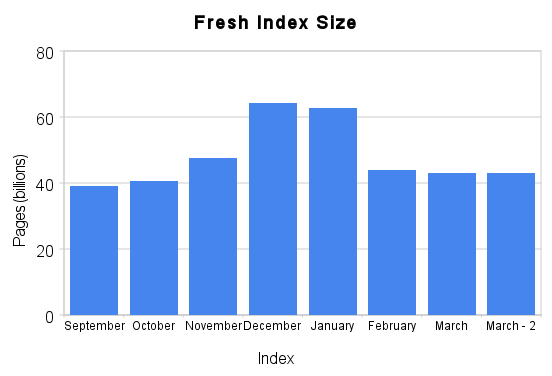
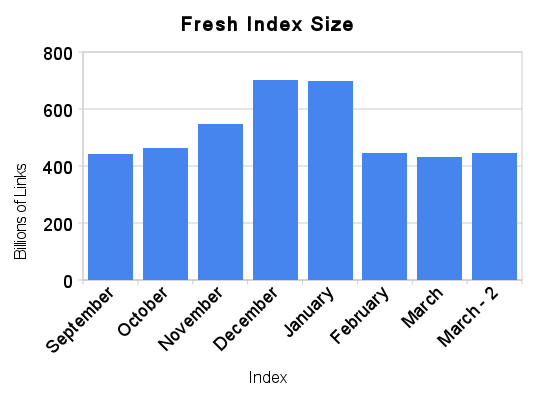
Note: "March - 2" is the most recent update (since we had two updates this month!)
At the end of January, in response to user feedback, we changed our methodology around what we update and include. One of the things we hear a lot is, "awesome index, but where's my site?" Or perhaps, "great links, but I know this site links to me, where is it?" Internally we also discovered a number of sites that generate technically distinct content, but with no extra value for our index. One of my favorite examples of such a site is tnid.org. So we cut pages like those, and made an extra effort to include sites which previously had been excluded. And the results are good:
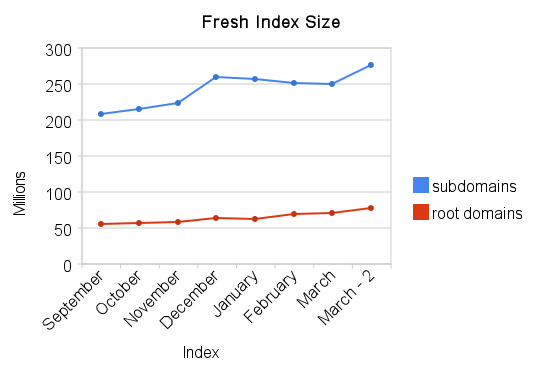
I'm actually really excited about this because our numbers are now very much in line with Netcraft's survey of active sites. But more importantly, I hope you are pleased too.
I've been spending time with Kate, our new VP of Engineering, bringing her up to speed about our technology. In addition to announcing the updated data, I also wanted to share some of our discussions. Below is a diagram of our monthly (well, 3-5 week) pipeline.

You can think of the open web as having essentially an endless supply of URLs to crawl, representing many petabytes of content. From that we select a much smaller set of pages to get updated content for on a monthly basis. In large part, this is due to politeness considerations: there's about 2.6 million seconds in a month, and most sites won't tolerate fetching one page a second by a bot. So we only can get updated content for so many pages in a month.
From the updated content we get, we discover a very large amount of new content, representing a petabyte or more of new data. From this we merge non-canonical forms, and remove duplicates, as well as synthesize some powerful metrics like Page Authority, Domain Authority, mozRank, etc.
Once we've got that data prepared, we drop our old (by then out of date) data, and push the updated information to our API. On about a monthly basis we turn over about 50 billion urls, representing hundreds of terabytes of information.
What Happened To Last Week's Update
In the spirit of TAGFEE, I feel like I need to take some responsibility for last week's late update, and explain what happened.
One of the big goals we've got is to give fresh data. One way we can do that is to shorten the amount of time between getting raw content and processing it. That corresponds to the "Newly Discovered Content" section of the chart above. For the last update we doubled the size of our infrastructure. In addition to doubling the number of computers we have running around analyzing and synthesizing data, it actually increased the coordination between those computers. If everyone has to talk to everyone else, and you double the number of people, you actually quadruple the number of relationships. This caused lots of problems we had to deal with at various times.
Another nasty side-effect of all of this was this made machine failures even more common than we experienced before. If you know anything about Amazon Web Services and Elastic Computer Cloud then you know that those instances go down a lot :) So we needed an extra four days to get the data out.
Fortunately we've taken this as an opportunity to improve our infrastructure, fault tolerance and lots of other good tech start-up buzz words. Which is one of the reasons we're able to get this update out so quickly after the previous one.
As always, we really appreciate feedback, so keep it coming!
![Convince Your Boss to Send You to MozCon 2025 [Plus Bonus Letter Template]](https://moz.rankious.com/_moz/images/blog/banners/eee4a4a8-d4aa-457e-80b1-0ffa186b88ff_2025-06-27-174747_coli.png?w=580&h=196&auto=compress%2Cformat&fit=crop&dm=1751046467&s=454333def17ba9d472d3d98b6786741e)
![How To Drive More Conversions With Fewer Clicks [MozCon 2025 Speaker Series]](https://moz.rankious.com/_moz/images/blog/banners/Mozcon2025_SpeakerBlogHeader_1180x400_RebeccaJackson_London.png?w=580&h=196&auto=compress%2Cformat&fit=crop&dm=1750097440&s=296c25041fd58804005c686dfd07b9d1)

Comments
Please keep your comments TAGFEE by following the community etiquette
Comments are closed. Got a burning question? Head to our Q&A section to start a new conversation.