

Rewriting the Beginner's Guide Part VIII: Search Engine Tools and Services
The author's views are entirely their own (excluding the unlikely event of hypnosis) and may not always reflect the views of Moz.
Over the past year, Rand Fishkin has been working on re-authoring and re-building the Beginner's Guide to Search Engine Optimization. Since he has been very busy doing other work lately, I decided to step in and pick up from where he left off. You can read more about this project here.
An Introduction to the Search Engines' Tools for Webmasters
To encourage webmasters to create sites and content in accessible ways, each of the major search engines have built support and guidance-focused services. Each provides varying levels of value to search marketers, but all of them are worthy of understanding. These tools provide data points and opportunities for exchanging information with the engines that are not provided anywhere else.
The sections below explain the common interactive elements that each of the major search engines support and identify why they are useful. There are enough details on each of these elements to warrant their own blog posts, but for the purposes of this guide, only the most crucial and valuable components will be discussed.
Common Search Engine Protocols
Sitemaps
Sitemaps are a formatted list of all of the pages on a given website. They are used to ensure that search engines can easily find the location of all of the webpages on a website and to assign each page a relative priority.
The sitemaps protocol (explained in detail at Sitemaps.org) is applicable to three different file formats:
XML - Extensible Markup Language (Recommended Format)
Pros - This is the most widely accepted format for sitemaps. It is extremely easy for search engines to parse and can be produced by a plethora of sitemap generators. Additionally, it allows for the most granular control of page parameters.
Cons - Relatively large file sizes. Since XML requires an open tag and a close tag around each element, files sizes suffer.
RSS - Really Simple Syndication or Rich Site Summary
Pros - Easy to maintain. RSS sitemaps can easily be coded to automatically update when new content is added.
Cons - Harder to manage. Although RSS is a dialect of XML, it is actually much harder to manage due to its updating properties.
Txt - Text File
Pros - Extremely easy. The text sitemap format is one URL per line up to 50,000 lines.
Cons - Does not provide the ability to add meta data to pages.
Sitemaps can either be submitted directly to the major search engines or have their location specified in robots.txt.
Robots.txt
The robots.txt file (a product of the Robots Exclusion Protocol) should be stored at a website's root directory (e.g., www.google.com/robots.txt). The file serves as an access guide for automated visitors (web robots). By using robots.txt, webmasters can indicate which areas of a site they would like to disallow bots from crawling as well as indicate the locations of sitemaps files (discussed below) and crawl-delay parameters. The following commands are available:
Meta Robots
The meta robots tag creates page-level instructions for search engine bots that govern everything from page inclusion to snippet controls and more.
The meta robots tag should be included in the head section of the HTML document.
Example of Meta Robots:
Rel="nofollow"
Nofollow is a common inline parameter that is adhered to by all of the major search engines. It is appended to links to prevent them from passing ranking power (or "link juice").
Example of nofollow:
Search Engine Tools
The following tools are provided free of charge by the major search engines and enable webmasters to have more control over how their content is indexed.
Google Webmaster Tools
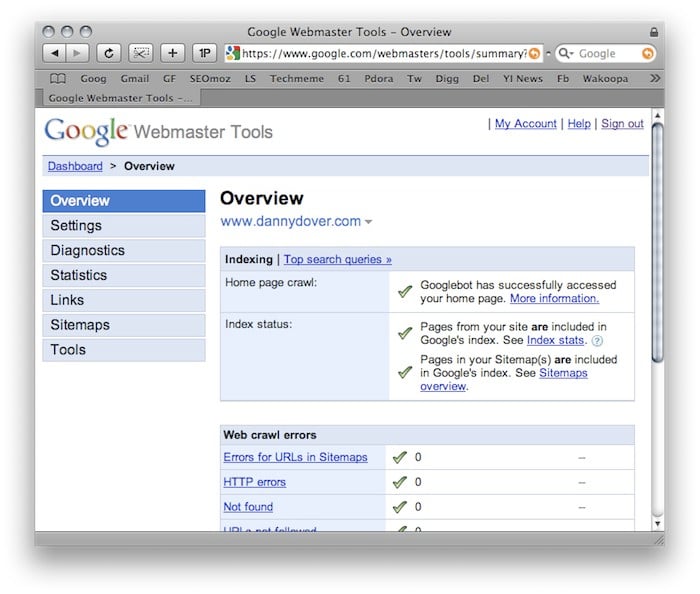
Google Webmaster Tools
Sign Up
Google Webmaster Tools Sign Up
Settings
Geographic target - If a given site targets users in a particular location, webmasters can provide Google with information that will help determine how that site appears in our country-specific search results, and also improve Google search results for geographic queries.
Preferred Domain - The preferred domain is the one that a webmaster would like used to index their site's pages. If a webmaster specifies a preferred domain as http://www.example.com and Google finds a link to that site that is formatted as http://example.com, Google will treat that link as if it were pointing at http://www.example.com.
Image Search - If a webmaster chooses to opt in to enhanced image search, Google may use tools such as Google Image Labeler to associate the images included in their site with labels that will improve indexing and search quality of those images.
Crawl Rate - The crawl rate affects the speed of Googlebot's requests during the crawl process. It has no effect on how often Googlebot crawls a given site. Google determines the recommended rate based on the number of pages on a website.
Diagnostics
Web Crawl - Web Crawl identifies problems Googlebot encountered when it crawls a given website. Specifically, it lists Sitemap errors, HTTP errors, nofollowed URLs, URLs restircted by robots.txt and URLs that time out.
Mobile Crawl - Identifies problems with mobile versions of websites.
Content Analysis - This analysis identifies search engine unfriendly HTML elements. Specifically, it lists meta description issues, title tag issues and non-indexable content issues.
Statistics
These statistics are a window into how Google sees a given website. Specifically, it identifies top search queries, crawl stats, subscriber stats, “What Googlebot sees” and Index stats.
Link Data
This section provides details on links. Specifically, it outlines, external links, internal links and sitelinks. Sitelinks are section links that sometimes appear under websites when they are especially applicable to a given query.
Sitemaps
This is the interface for submitting and managing sitemaps directly with Google.
Yahoo! Site Explorer
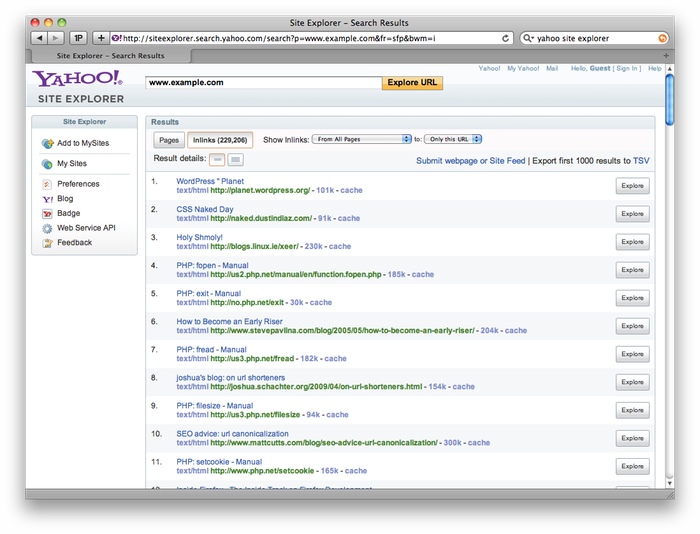
Yahoo! Site Explorer
Sign Up
Yahoo! Site Explorer Sign Up
Features
Statistics - These statistics are very basic and include data like the title tag of a homepage and number of indexed pages for the given site.
Feeds - This interface provides a way to directly submit feeds to Yahoo! for inclusion into its index. This is mostly useful for websites with frequently updated blogs.
Actions - This simplistic interface allows webmasters to delete URLs from Yahoo’s index and to specify dynamic URLs. The latter is especially important because Yahoo! traditionally has a lot of difficulty differentiating dynamic URLs.
Live Webmaster Tools
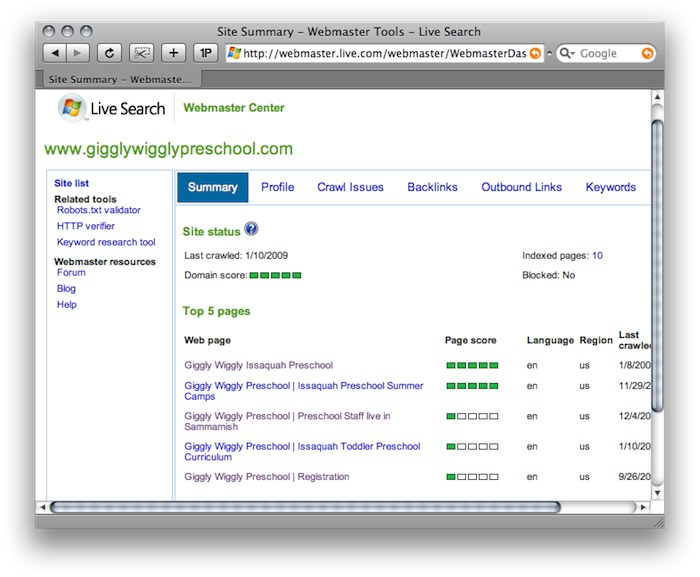
Sign Up
Live Webmaster Center
Features
Profile - This interface provides a way for webmasters to specify the location of sitemaps and a form to provide contact information so Live can contact them if it encounters problems while crawling their website.
Crawl Issues - This helpful section identifies HTTP status code errors, Robots.txt problems, long dynamic URLs, unsupported content type and, most importantly, pages infected with malware.
Backlinks - This section allows webmasters to find out which webpages (including their own) are linking to a given website.
Outbound Links - Similarly to the aforementioned section, this interface allows webmasters to view all outbound pages on a given webpage.
Keywords - This section allows webmasters to discover which of their webpages are deemed relevant to specific queries.
Sitemaps - This is the interface for submitting and managing sitemaps directly to Microsoft.
It is a relatively recent occurrence that search engines have provided ways for webmasters to interact directly with crawlers. While this relationship is still not optimal, the search engines have made great strides toward opening their proprietary indices. This has been very helpful for webmasters who now rely so much on search driven traffic.
As always, comments and constructive criticism are appreciated. You'll note that I'm trying to go back to making this more of a true "beginner's" guide, as I'm concerned that the previous guide may have gone a bit too in-depth. Hopefully between Rand and me, we can finish this mammoth undertaking :)
An Introduction to the Search Engines' Tools for Webmasters
To encourage webmasters to create sites and content in accessible ways, each of the major search engines have built support and guidance-focused services. Each provides varying levels of value to search marketers, but all of them are worthy of understanding. These tools provide data points and opportunities for exchanging information with the engines that are not provided anywhere else.
The sections below explain the common interactive elements that each of the major search engines support and identify why they are useful. There are enough details on each of these elements to warrant their own blog posts, but for the purposes of this guide, only the most crucial and valuable components will be discussed.
Common Search Engine Protocols
Sitemaps
Sitemaps are a formatted list of all of the pages on a given website. They are used to ensure that search engines can easily find the location of all of the webpages on a website and to assign each page a relative priority.
The sitemaps protocol (explained in detail at Sitemaps.org) is applicable to three different file formats:
XML - Extensible Markup Language (Recommended Format)
Pros - This is the most widely accepted format for sitemaps. It is extremely easy for search engines to parse and can be produced by a plethora of sitemap generators. Additionally, it allows for the most granular control of page parameters.
Cons - Relatively large file sizes. Since XML requires an open tag and a close tag around each element, files sizes suffer.
RSS - Really Simple Syndication or Rich Site Summary
Pros - Easy to maintain. RSS sitemaps can easily be coded to automatically update when new content is added.
Cons - Harder to manage. Although RSS is a dialect of XML, it is actually much harder to manage due to its updating properties.
Txt - Text File
Pros - Extremely easy. The text sitemap format is one URL per line up to 50,000 lines.
Cons - Does not provide the ability to add meta data to pages.
Sitemaps can either be submitted directly to the major search engines or have their location specified in robots.txt.
Robots.txt
The robots.txt file (a product of the Robots Exclusion Protocol) should be stored at a website's root directory (e.g., www.google.com/robots.txt). The file serves as an access guide for automated visitors (web robots). By using robots.txt, webmasters can indicate which areas of a site they would like to disallow bots from crawling as well as indicate the locations of sitemaps files (discussed below) and crawl-delay parameters. The following commands are available:
- Disallow - Prevents compliant robots from accessing specific pages or folders
- Sitemap - Indicates the location of a website's sitemap or sitemaps
- Crawl Delay - Indicates the speed (in milliseconds) at which a robot can crawl a server.
Warning: It is very important to realize that not all web robots follow robots.txt. People with bad intentions (e.g., e-mail address scrapers) build bots that don’t follow this protocol and in extreme cases can use it to identify the location of private information. For this reason, it is recommended that the location of administration sections and other private sections of publicly accessible websites not be included in the robots.txt. Instead, these pages can utilize the meta robots tag (discussed next) to keep the major search engines from indexing their high risk content.#Robots.txt www.example.com/robots.txt
User-agent: *
Disallow:
# Don't allow spambot to crawl any pages
User-agent: spambot
Disallow: /
sitemap:www.example.com/sitemap.xml
Meta Robots
The meta robots tag creates page-level instructions for search engine bots that govern everything from page inclusion to snippet controls and more.
The meta robots tag should be included in the head section of the HTML document.
Example of Meta Robots:
<html>
<head>
<title>The Best Webpage on the Internet</title>
<meta name=”ROBOT NAME” content=”ARGUMENTS” />
</head>
<body>
<h1>Hello World</h1>
</body>
</html>
| Use Case | Robots.txt | META/ X-Robots-Tag | Other | Supported By |
| Allow access to your content | Allow | FOLLOW INDEX |
Google Yahoo Microsoft |
|
| Disallow access to your content | Disallow |
NOINDEX NOFOLLOW |
Google Yahoo Microsoft |
|
| Disallow access to index images on the page | NOIMAGEINDEX | |||
| Disallow the display of a cached version of your content in the SERP | NOARCHIVE | Google Yahoo Microsoft |
||
| Disallow the creation of a description for this content in the SERP | NOSNIPPET | Google Yahoo Microsoft |
||
| Disallow the translation of your content into other languages | NOTRANSLATE | |||
| Do not follow or give weight to links within this content | NOFOLLOW | a href attribute: rel=NOFOLLOW |
Google Yahoo Microsoft |
|
| Do not use the Open Directory Project (ODP) to create descriptions for your content in the SERP | NOODP | Google Yahoo Microsoft |
||
| Do not use the Yahoo Directory to create descriptions for your content in the SERP | NOYDIR | Yahoo | ||
| Do not index this specific element within an HTML page | class=robots-nocontent | Yahoo | ||
| Stop indexing this content after a specific date | UNAVAILABLE_AFTER | |||
| Specify a sitemap file or a sitemap index file | Sitemap | Google Yahoo Microsoft |
||
| Specify how frequently a crawler may access your website | Crawl-Delay |
Google WMT | Yahoo Microsoft |
|
| Authenticate the identity of the crawler | Reverse DNS Lookup | Google Yahoo Microsoft |
||
| Request removal of your content from the engine's index | Google WMT Yahoo SE Microsoft WMT |
Google Yahoo Microsoft |
Source: Jane & Robot - Managing Robots' Access to Your Website
Rel="nofollow"
Nofollow is a common inline parameter that is adhered to by all of the major search engines. It is appended to links to prevent them from passing ranking power (or "link juice").
Example of nofollow:
<a href=”http://www.example.com” title=”Example”
rel=”nofollow”>Example Link</a>Search Engine Tools
The following tools are provided free of charge by the major search engines and enable webmasters to have more control over how their content is indexed.
Google Webmaster Tools
Google Webmaster Tools
Sign Up
Google Webmaster Tools Sign Up
Settings
Geographic target - If a given site targets users in a particular location, webmasters can provide Google with information that will help determine how that site appears in our country-specific search results, and also improve Google search results for geographic queries.
Preferred Domain - The preferred domain is the one that a webmaster would like used to index their site's pages. If a webmaster specifies a preferred domain as http://www.example.com and Google finds a link to that site that is formatted as http://example.com, Google will treat that link as if it were pointing at http://www.example.com.
Image Search - If a webmaster chooses to opt in to enhanced image search, Google may use tools such as Google Image Labeler to associate the images included in their site with labels that will improve indexing and search quality of those images.
Crawl Rate - The crawl rate affects the speed of Googlebot's requests during the crawl process. It has no effect on how often Googlebot crawls a given site. Google determines the recommended rate based on the number of pages on a website.
Diagnostics
Web Crawl - Web Crawl identifies problems Googlebot encountered when it crawls a given website. Specifically, it lists Sitemap errors, HTTP errors, nofollowed URLs, URLs restircted by robots.txt and URLs that time out.
Mobile Crawl - Identifies problems with mobile versions of websites.
Content Analysis - This analysis identifies search engine unfriendly HTML elements. Specifically, it lists meta description issues, title tag issues and non-indexable content issues.
Statistics
These statistics are a window into how Google sees a given website. Specifically, it identifies top search queries, crawl stats, subscriber stats, “What Googlebot sees” and Index stats.
Link Data
This section provides details on links. Specifically, it outlines, external links, internal links and sitelinks. Sitelinks are section links that sometimes appear under websites when they are especially applicable to a given query.
Sitemaps
This is the interface for submitting and managing sitemaps directly with Google.
Yahoo! Site Explorer
Yahoo! Site Explorer
Sign Up
Yahoo! Site Explorer Sign Up
Features
Statistics - These statistics are very basic and include data like the title tag of a homepage and number of indexed pages for the given site.
Feeds - This interface provides a way to directly submit feeds to Yahoo! for inclusion into its index. This is mostly useful for websites with frequently updated blogs.
Actions - This simplistic interface allows webmasters to delete URLs from Yahoo’s index and to specify dynamic URLs. The latter is especially important because Yahoo! traditionally has a lot of difficulty differentiating dynamic URLs.
Live Webmaster Tools
Live Webmaster Center
Sign Up
Live Webmaster Center
Features
Profile - This interface provides a way for webmasters to specify the location of sitemaps and a form to provide contact information so Live can contact them if it encounters problems while crawling their website.
Crawl Issues - This helpful section identifies HTTP status code errors, Robots.txt problems, long dynamic URLs, unsupported content type and, most importantly, pages infected with malware.
Backlinks - This section allows webmasters to find out which webpages (including their own) are linking to a given website.
Outbound Links - Similarly to the aforementioned section, this interface allows webmasters to view all outbound pages on a given webpage.
Keywords - This section allows webmasters to discover which of their webpages are deemed relevant to specific queries.
Sitemaps - This is the interface for submitting and managing sitemaps directly to Microsoft.
It is a relatively recent occurrence that search engines have provided ways for webmasters to interact directly with crawlers. While this relationship is still not optimal, the search engines have made great strides toward opening their proprietary indices. This has been very helpful for webmasters who now rely so much on search driven traffic.
As always, comments and constructive criticism are appreciated. You'll note that I'm trying to go back to making this more of a true "beginner's" guide, as I'm concerned that the previous guide may have gone a bit too in-depth. Hopefully between Rand and me, we can finish this mammoth undertaking :)



Comments
Please keep your comments TAGFEE by following the community etiquette
Comments are closed. Got a burning question? Head to our Q&A section to start a new conversation.