

Serious Robots.txt Misuse & High Impact Solutions
Some of the Internet's most important pages from many of the most linked-to domains, are blocked by a robots.txt file. Does your website misuse the robots.txt file, too? Find out how search engines really treat robots.txt blocked files, entertain yourself with a few seriously flawed implementation examples and learn how to avoid the same mistakes yourself.
The robots.txt protocol was established in 1994 as a way for webmasters to indicate which pages and directories should not be accessed by bots. To this day, respectable bots adhere to the entries in the file... but only to a point.
Your Pages Could Still Show Up in the SERPs
Bots that follow the instructions of the robots.txt file, including Google and the other big guys, won’t index the content of the page but they may still put the page in their index. We’ve all seen these limited listings in the Google SERPs. Below are two examples of pages that have been excluded using the robots.txt file yet still show up in Google.
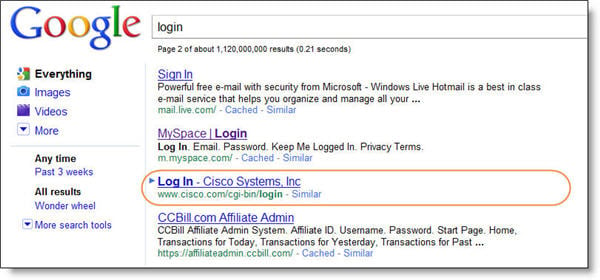
Cisco Login Page
The below highlighted Cisco login page is blocked in the robots.txt file, but shows up with a limited listing on the second page of a Google search for ‘login’. Note that the Title Tag and URL are included in the listing. The only thing missing is the Meta Description or a snippet of text from the page.
WordPress’s Next Blog Page
One of WordPress.com’s 100 most popular pages (in terms of linking root domains) is www.wordpress.com/next. It is blocked by the robots.txt file, yet it still appears in position four in Google for the query ‘next blog’.
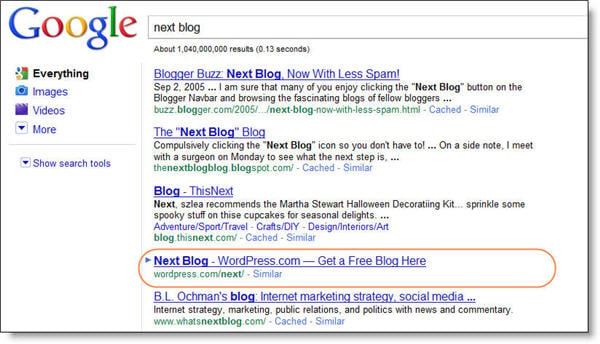
As you can see, adding an entry to the robots.txt file is not an effective way of keeping a page out of Google’s search results pages.
Robots.txt Usage Can Block Inbound Link Effectiveness
The thing about using the robots.txt file to block search engine indexing is not only that it is quite ineffective, but that it also cuts off your inbound link flow. When you block a page using the robots.txt file, the search engines don’t index the contents (OR LINKS!) on the page. This means that if you have inbound links to the page, this link juice cannot flow to other pages. You create a dead end.
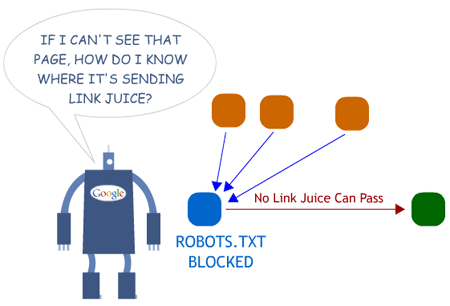
(If this depiction of Googlebot looks familiar, that's because you've seen it before! Thanks Rand.)
Even though the inbound links to the blocked page likely have some benefit to the domain overall, this inbound link value is not being utilized to its fullest potential. You are missing an opportunity to pass some internal link value from the blocked page to more important internal pages.
3 Big Sites with Blocked Opportunity in the Robots.txt File
I've scoured the net looking for the best bloopers possible. Starting with the SEOmoz Top 500 list, I hammered OpenSiteExplorer in search of heart-stopping Top Pages lists like this:
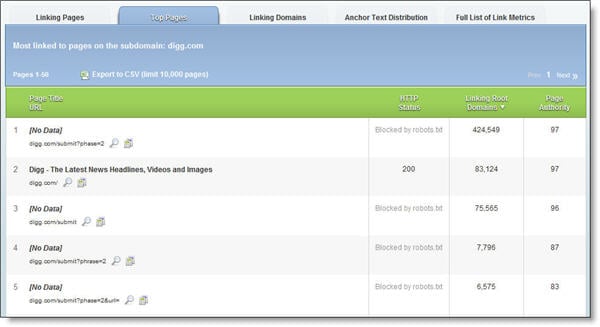
Ouch, Digg. That's a lot of lost link love!
This leads us to our first seriously flawed example of robots.txt use.
#1 - Digg.com
Digg.com used the robots.txt to create as much disadvantage as possible by blocking a page with an astounding 425,000 unique linking root domains, the "Submit to Digg" page.
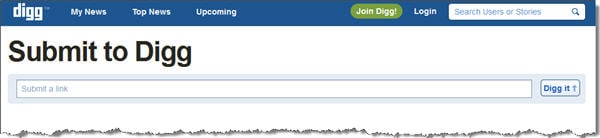
The good news for Digg is that from the time I started researching for this post to now, they've removed the most harmful entries from their robots.txt file. Since you can't see this example live, I've included Google's latest cache of Digg's robots.txt file and a look at Google's listing for the submit page(s).
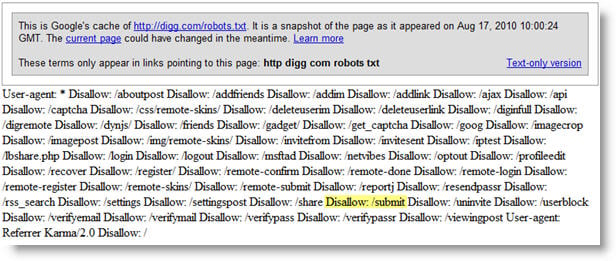
As you can see, Google hasn't begun indexing the content that Digg.com had previously removed in the robots.txt.
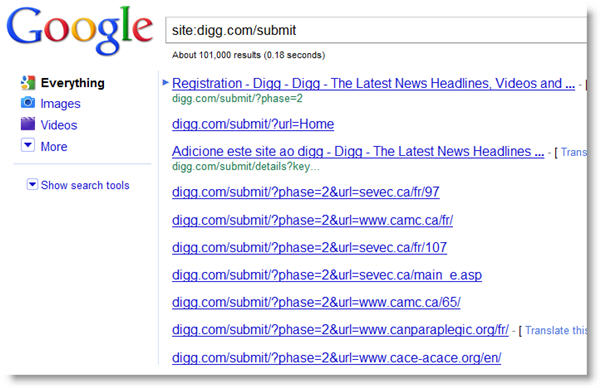
I would expect Digg to see a nice jump in search traffic following the removal of it's most linked to pages from the robots.txt file. They should probably keep these pages out of the index with the robots meta tag, 'noindex', so as not to flood the engines with redundant content. This move would ensure that they benefit from the link juice without flooding the search engine indexes.
If you aren't up to speed on the use of noindex, all you have to do is place the following meta tag into the <head> section of your page:
<meta name="robots" content="noindex, follow">
Additionally, by adding 'follow' to the tag you are telling the bots to not index that particular page, but allowing them to follow the links on the page. This is usually the best scenario as it means that the link juice will flow to the followed links on the page. Take for example a paginated search results page. You probably don't want that specific page to show up in the search results as the contents of page 5 of that particular search is going to change day to day. But by using the robots noindex, follow the links to products (or jobs in this example from Simply Hired) will be followed and hopefully indexed.
Alternitavely you can use "noindex, nofollow" but that's a mostly pointless endeavor as you're blocking link juice as with the robots.txt.
#2 - Blogger.com & Blogspot.com
Blogger and Blogspot, both owned by Google, show us that everyone has room for improvement. The way these two domains are interconnected does not utilize best practices and much link love is lost along the way.
Blogger.com is the brand behind Google's blogging platform, with subdomains hosted at 'yourblog.blogspot.com'. The link juice blockage and robots.txt issue that arises here is that www.blogspot.com is entirely blocked with the robots.txt. As if that wasn't enough, when you try to pull up the home page of Blogspot, you are 302 redirected to Blogger.com.
Note: All subdomains, aside from 'www', are accessible to robots.
A better implementation here would be a straight 301 redirect from the home page of Blogspot.com to the main landing page on Blogger.com. The robots.txt entry should be removed altogether. This small change would unlock the hidden power of more than 4,600 unique linking domains. That is a good chunk of links.
#3 - IBM
IBM has a page with 1001 unique linking domains that is blocked by the robots.txt file. Not only is the page blocked in the robots.txt but it also does a triple-hop 302 to another location, show below.
When a popular page is expired or moved, the best solution is usually a 301 redirect to the most suitable final replacement.
Superior Solutions to the Robots.txt
In the big site examples highlighted above, we’ve covered some misuses of the robots.txt file. Some scenarios weren't covered. Below is a list of effective solutions to keep content out of the search engine index without link juice leak.
Noindex
In most cases, the best replacement for robots.txt exclusion is the robots meta tag. By adding 'noindex' and making sure that you DON'T add 'nofollow', your pages will stay out of the search engine results but will pass link value. This is a win/win!
301 Redirect
The robots.txt file is no place to list old worn out pages. If the page has expired (deleted, moved, etc.) don't just block it. Redirect that page using a 301 to the most relevant replacement. Get more information about redirection from the Knowledge Center.
Canonical Tag
Don't block your duplicate page versions in the robots.txt. Use the canonical tag to keep the extra versions out of the index and to consolidate the link value. Whenever possible. Get more information from the Knowledge Center about canonicalization and the use of the rel=canonical tag.
Password Protection
The robots.txt file is not an effective way of keeping confidential information out of the hands of others. If you are making confidential information accessible on the web, password protect it. If you have a login screen, go ahead and add the 'noindex' meta tag to the page. If you expect a lot of inbound links to this page from users, be sure to link to some key internal pages from the login page. This way, you will pass the link juice through.
Effective Robots.txt Usage
The best way to use a robots.txt file is to not use it at all. Well... almost. Use it to indicate that robots have full access to all files on your website and to direct robots to your sitemap.xml file. That’s it.
Your robots.txt file should look like this:
-----------------
User-agent: *
Disallow:
Sitemap: http://www.yoursite.com/sitemap.xml
-----------------
The Bad Bots
Earlier in the post I mentioned that "Bots that follow the instructions of the robots.txt file," which means that there are bots that don't adhere to the robots.txt at all. So while you're doing a good job of keeping out the good bots, you're doing a horrible job of keeping out the "bad" bots. Additionally, filtering to only allow bot access to Google/Bing isn't recommend for three reasons:
- The engines change/update bot names frequently (e.g. the Bing bot name change recently)
- Engines employ multiple types of bots for different types of content (e.g. images, video, mobile, etc.)
- New engines/content discovery technologies getting off the ground stand even less of a chance with institutionalized preferences for existing user agents only (e.g. Blekko, Yandex, etc.) and search competition is good for the industry.
Competitors
If your competitors are SEO savvy in any way shape or form, they're looking at your robots.txt file to see what they can uncover. Let's say you're working on a new redesign, or a whole new product line and you have a line in your robots.txt file that disallows bots from "indexing" it. If a competitor comes along, checks out the file and sees this directory called "/newproducttest" then they've just hit the jackpot! Better to keep that on a staging server, or behind a login. Don't give all your secrets away in this one tiny file.
Handling Non-HTML & System Content
- It isn't necessary to block .js and .css files in your robots.txt. The search engines won't index them, but sometimes they like the ability to analyze them so it is good to keep access open.
- To restrict robot access to non-HTML documents like PDF files, you can use the x-robots tag in the HTTP Header. (Thanks to Bill Nordwall for pointing this out in the comments.)
- Images! Every website has background images or images used for styling that you don't want to have indexed. Make sure these images are displayed through the CSS and not using the <img> tag as much as possible. This will keep them from being indexed, rather than having to disallow the "/style/images" folder from the robots.txt.
- A good way to determine whether the search engines are even trying to access your non-HTML files is to check your log files for bot activity.
More Reading
Both Rand Fishkin & Andy Beard have covered robots.txt misuse in the past. Take note of the publish dates and be careful with both of these posts, though, because they were written before the practice of internal PR sculpting with the nofollow link attribute was discouraged. In other words, these are a little dated but the concept descriptions are solid.
- Rand’s: Don’t Accidentally Block Link Juice with Robots.txt
- Andy’s: SEO Linking Gotchas Even the Pros Make
Action Items
- Pull up your website’s robots.txt file(s). If anything is disallowed, keep reading.
- Check out the Top Pages report in OSE to see how serious your missed opportunity is. This will help you decide how much priority to give this issue compared to your other projects.
- Add the noindex meta tag to pages that you want excluded from the search engine index.
- 301 redirect the pages on your domain that don’t need to exist anymore and were previously excluded using the robots.txt file.
- Add the canonical tag to duplicate pages previously robots.txt’d.
- Get more search traffic.
Happy Optimizing!
(post edited 10/12/10 @ 5:20AM to reflect x-robots protocol for non-html pages)
The author's views are entirely their own (excluding the unlikely event of hypnosis) and may not always reflect the views of Moz.


Comments
Please keep your comments TAGFEE by following the community etiquette
Comments are closed. Got a burning question? Head to our Q&A section to start a new conversation.