
The Freshest Linkscape Data Ever
Since the launch of Open Site Explorer and our API update, Chas, Ben and I have invested a lot of time and energy into improving the freshness and completeness of Linkscape's data. I'm pleased to announce that we've updated the Linkcape index with crawl data that's between two and five weeks old—the freshest it's ever been. We've also changed how we select pages, in order to get deeper coverage on important domains and waste less time on prolific but unimportant domains.
You may recall Rand's recent post about prioritizing the best pages to crawl, and mine about churn in the web. We've applied some of the principles from these posts to our own crawling and indexing. Rand discussed how crawlers might discover good content on a domain by selecting well-linked-to entry points:
In the past, we've selected pages to crawl based purely on mozRank. That turned out to favor some unsavory elements (you know who you are :P). Now, we look at each domain and determine how authoritative it is. From there we select pages using the principle illustrated above: Highly linked-to pages—the homepage, category pages, important pieces of deep content—link to other important pages we should crawl. From intuition and experience we believe this gives the right behavior to crawl like a search engine would.
In a past post, I discussed the importance of fresh data. After all, if 25% of pages on the web disappear after one month, data collected two or more months ago just isn't actionable.
What this means for you is that all our tools powered by Linkscape will provide fresher, more relevant data, and we'll have better coverage than ever. This includes things like:
As well as products and tools developed outside SEOmoz using either the free or paid API: There are plenty more. In fact, you could build one too!
Because I know how much everyone likes numbers, here are some stats from our latest index:
Our next update is scheduled for March 11. But we'll update the index before then if the data is ready early :)
As always, keep the feedback coming. With our own toolset relying on this data, and dozens of partners using our API to develop their own applications, it's critical that we hear what you guys think.
NOTE: we're still updating the top 500 list at the moment. We'll tweet when that's ready.
You may recall Rand's recent post about prioritizing the best pages to crawl, and mine about churn in the web. We've applied some of the principles from these posts to our own crawling and indexing. Rand discussed how crawlers might discover good content on a domain by selecting well-linked-to entry points:
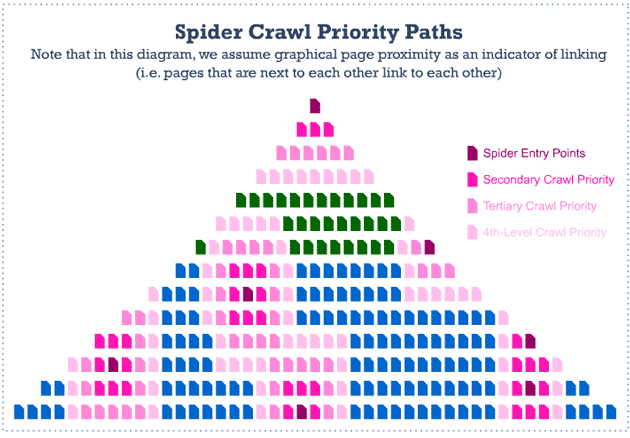
In the past, we've selected pages to crawl based purely on mozRank. That turned out to favor some unsavory elements (you know who you are :P). Now, we look at each domain and determine how authoritative it is. From there we select pages using the principle illustrated above: Highly linked-to pages—the homepage, category pages, important pieces of deep content—link to other important pages we should crawl. From intuition and experience we believe this gives the right behavior to crawl like a search engine would.
In a past post, I discussed the importance of fresh data. After all, if 25% of pages on the web disappear after one month, data collected two or more months ago just isn't actionable.
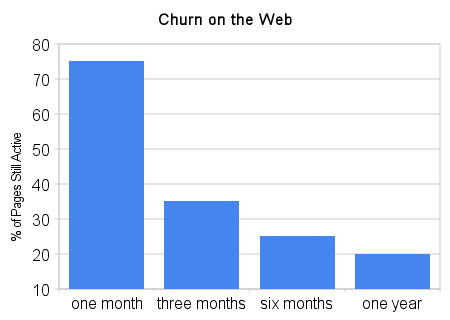
What this means for you is that all our tools powered by Linkscape will provide fresher, more relevant data, and we'll have better coverage than ever. This includes things like:
As well as products and tools developed outside SEOmoz using either the free or paid API: There are plenty more. In fact, you could build one too!
Because I know how much everyone likes numbers, here are some stats from our latest index:
- URLs: 43,813,674,337
- Subdomains: 251,428,688
- Root Domains: 69,881,887
- Links: 9,204,328,536,611
Our next update is scheduled for March 11. But we'll update the index before then if the data is ready early :)
As always, keep the feedback coming. With our own toolset relying on this data, and dozens of partners using our API to develop their own applications, it's critical that we hear what you guys think.
NOTE: we're still updating the top 500 list at the moment. We'll tweet when that's ready.
![Convince Your Boss to Send You to MozCon 2025 [Plus Bonus Letter Template]](https://moz.rankious.com/_moz/images/blog/banners/eee4a4a8-d4aa-457e-80b1-0ffa186b88ff_2025-06-27-174747_coli.png?w=580&h=196&auto=compress%2Cformat&fit=crop&dm=1751046467&s=454333def17ba9d472d3d98b6786741e)
![How To Drive More Conversions With Fewer Clicks [MozCon 2025 Speaker Series]](https://moz.rankious.com/_moz/images/blog/banners/Mozcon2025_SpeakerBlogHeader_1180x400_RebeccaJackson_London.png?w=580&h=196&auto=compress%2Cformat&fit=crop&dm=1750097440&s=296c25041fd58804005c686dfd07b9d1)

Comments
Please keep your comments TAGFEE by following the community etiquette
Comments are closed. Got a burning question? Head to our Q&A section to start a new conversation.