

What Wikipedia Can Teach Us About Natural Linking
This YouMoz entry was submitted by one of our community members. The author’s views are entirely their own (excluding an unlikely case of hypnosis) and may not reflect the views of Moz.
 There have been a few link building articles I've read that have included these four words: "link building is tough." Since April (post-Penguin), I think many SEOs and link builders will agree that it's tougher than ever, with Google placing more emphasis on natural links. This is especially tough for link builders, as even via white-hat methods, not all links are arguably 'natural,' and if a site was doing fine purely through receiving natural links, then it may not necessarily need link builders to work on it at all!
There have been a few link building articles I've read that have included these four words: "link building is tough." Since April (post-Penguin), I think many SEOs and link builders will agree that it's tougher than ever, with Google placing more emphasis on natural links. This is especially tough for link builders, as even via white-hat methods, not all links are arguably 'natural,' and if a site was doing fine purely through receiving natural links, then it may not necessarily need link builders to work on it at all!
It makes sense that Google only wants its algorithm to consider natural links. Google has always welcomed natural links, and in a perfect world, there'd be no unnatural links. Jon Cooper summed this up perfectly when he wrote that "hyperlinks were the best indicators of both authority and relevance because they were natural" (original emphasis) in reference to Larry and Sergey's original paper on how links could be used to influence a search engine's results. (Also, bear in mind that Jon's post was published before Penguin struck - I make this point because the title of Jon's post is "The Natural Link Is Making A Comeback," and it looks like Jon was right.)
A lot of the talk surrounding Google Penguin comes down to having a more natural inbound link profile. Of course, if you can't be 100% natural, the next best thing is to look 100% natural. And I don't mean that in a black-hat context - Ross Hudgens wrote a great post on varying anchor text, of which the title of the post says it all: you can unnaturally naturally vary your anchor text.
But easier said than done. As Ross argues, how do we know how to unnaturally naturally vary anchor text when we don't really know what the limits or thresholds are? What's too much and over-doing it? What's too little and spreading yourself too thin needlessly? Are there sites out there that have perfectly natural anchor text that rank well, too?
And then it hit me...
Hypothesis
What site has some of the strongest organic rankings ever and has a LOT of links, but has probably never spent a penny on link building activities? Wikipedia.
A few months ago, a study highlighted just how much Wikipedia dominates the SERPs. In this particular study, Wikipedia ranked on page 1 for 99% of the 1,000 keywords considered, and ranked in the 1st position for 56% of them. And yet it doesn't actively 'do' link building. Post-Penguin, it's ranking just as well as ever, which is obvious because it hasn't been overly-SEOed, because its inbound links are natural.
Oh and on top of that, as I type this, according to Open Site Explorer, its DA (Domain Authority) is 100 and the wikipedia.org root domain has nearly 750 billion links pointing to it from nearly 3 million linking root domains. I'm sure Captain Obvious is happy to point out that that's a lot of links. It's enough to make you sick, isn't it?
Of course, Wikipedia's good rankings might be down to numerous other factors beyond inbound links, including the passing of link juice via internal linking (i.e. Wikipedia articles linking to other Wikipedia articles). I would have also added the fact that Wikipedia applies nofollow to all outbound links and therefore hogs all the PageRanky goodness it receives from inbound links, but this may not factor into things at all, with Ian Lurie reporting last year that PageRank can no longer be sculpted through using nofollow.
Either way, Wikipedia arguably has the strongest natural inbound link profile of any website on the Web. Although we can't all be Wikipedia, we can certainly learn lessons from its inbound link profile nonetheless. After all, for all we know, Google might use a site like Wikipedia as a basis for how natural links should look, behave, interact and exist and then factor that into algorithm updates like Google Penguin.
Disclaimer: There have been reports that Google does treat Wikipedia differently to how it'd treat a regular commercial site, for example. Therefore, please bear in mind that the following findings aren't necessarily the be-all-and-end-all of how natural links may affect the rankings of a website - personally though, either way, I still think this makes for an interesting study!
Method
In this post, I will grab 15 Wikipedia pages at random, using the 'Random article' link (en.wikipedia.org/wiki/Special:Random) on the en.wikipedia.org sub-domain. Then, using Open Site Explorer (OSE), I will take a look at each page's:
- Link authority
- Link relevancy
- Anchor text distribution
- Dofollow/nofollow ratio
- Social signals
Before publishing this post, one of the SEOmoz team wanted me to mention that July's Mozscape Update contains considerably less URLs than previous months (apparently June's data was twice the size of the July OSE dataset). As this research was carried out in June, please bear in mind that if you try to replicate the results, you may see considerably different data.
Sample
So here they are... the 15 pages I chose at random to analyse:
- Mike Connelly
- Carl English
- Henry Ford Bridge
- Pacific Southwest Baseball League
- Alpena County Regional Airport
- Yaya Diallo
- Opening lead
- Hot Pants Explosion
- Mudumu National Park
- Henry Davis Pochin
- Sargon Boulus
- Ervil LeBaron
- Roger Goode
- Llanview
- Pali-Aike Volcanic Field
As you can see, they are mostly pages that refer to people (past and present) and places (real and even fictional) with the exception of two of them: "Opening lead" is terminological and "Hot Pants Explosion" is a song!
Unfortunately, none of them are what could be considered pages that would rank for commercial terms, e.g. the Wikipedia page for "Payday loan." I mention this because in those instances, Wikipedia is often considered to be a competing site - after all, it may be occupying the space in the SERPs for a commercially competitive keyword. While I think it would have been interesting to have included one or two, in my opinion it shouldn't make a difference, simply because I can't see how there would be any significant difference in the inbound link profiles between Wikipedia pages that do or do not rank for commercial terms.
Also, I should be honest here and point out that these weren't the first 15 pages I came across. I only wanted to include those that had sufficient data according to OSE, i.e. those with at least 1 external linking root domain (LRD). What's interesting is that I must have come across about 50 pages* before I had my 15 pages to analyse. This suggests that from a random sample, about 30% of Wikipedia pages have more than 1 inbound link pointing to them, but the remaining 70% have just 1 or 0 inbound links from external websites.
* I must admit that I didn't count while I was going along unfortunately, so please bear in mind that this is an approximation.
Findings
First of all, here is some of the data at a glance for each page, including PageRank, Page Authority, the number of links and LRDs and their ranking in Google.co.uk:
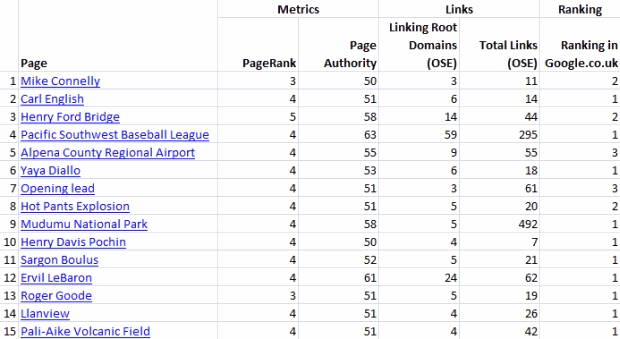
For these 15 pages, PageRank ranges from 3 to 5 (mode value: 4) and Page Authority ranges from 50 to 61 (median value: 51). It's also interesting to note that 10 of them were ranking at 1st in Google.co.uk when I checked them, with the other 5 ranking 2nd or 3rd - so nothing below the 3rd position!
But more specifically, let's take a look at the various link factors:
Link authority
In terms of authority, I looked at the Page Authority (PA) and Domain Authority (DA) across all 15 pages' inbound links and charted the results.
For those of you who saw it, this might remind you of the bar charts of the Google Penguin analysis by Microsite Masters, where they charted and compared the percentages of anchor text and relevancy between sites that had been affected and unaffected by Penguin. I thought I'd try a similar thing.
First up, the PA:

The PA is towards the left-hand side (mostly 1-50 overall). I can only surmise that this is because the inbound links are coming from either new pages or non-authoritative pages (insofar as they are not the homepage or main pages, but links buried deeper within the sites' architecture - e.g. archived blog posts). The highest PA score I found was 53.
Next up, the DA:

This is more spread out than the PA stats, but still heavier towards the lower end of the scale, with the majority of links coming from sites with a DA score between 11 and 20. However this time, there are still a noteworthy number of links with a score above 50, and even as high as the 80s and 90s. There's even two DA 100s: The Guardian and WordPress.
I was actually quite surprised by these findings. You'd think a site like Wikipedia would have some damn good links, but at an individual page level, some of the linking sites are quite low in terms of PA and DA. But then again, I guess this backs up the thinking that if a site's inbound link profile is mainly made up of only high PA/DA sites then it's likely that something fishy could be going on, with links being built solely to game PageRank and influence rankings. I remember reading somewhere that the average PageRank score across the Web is 1, so heavy PA and DA in the 11-20 region matches that theory to an extent.
Link relevancy
As relevancy is subjective, it's difficult to use a tool in the way that you'd use one to determine something like link authority. So this time, I looked at each page's inbound link profiles and wanted to give a few observations and examples of what I found.
Overall and generally speaking, the linking sites/pages were relevant to the Wikipedia page being linked to, e.g. "Opening lead" is linked to from a bridge site. If not 100% directly relevant then it would still be on-topic, e.g. "Hot Pants Explosion" is linked to from a general music site as well as lyrics and radio websites.
There wasn't just relevancy in terms of the subject or topic, either: the "Mudumu National Park" page was linked to from Namibian websites, so there is geographical and location-based relevancy, too.
Funnily enough, there are still non-relevant sites linking to some of the pages within the sample. For example, the "Pacific Southwest Baseball League" page is linked to from websites supposedly dedicated to topics including insurance, automotive and identity theft. This was a case of the sites scraping Wikipedia articles that were themselves linking to the Wikipedia pages. I guess no matter what happens, as webmasters cannot be 100% in control of their websites' inbound links, you have to allow for some non-relevancy, even when it comes to 'natural' links.
Anchor text distribution
The findings from the anchor text distribution are interesting - and seem to go against most of the current thinking behind a lot of the recovery advice surrounding Penguin.
A lot of Penguin recovery advice articles claim that one of Penguin's favourite things (or least favourite things, depending on how you look at it) is too much exact match anchor text. Here's one article saying just that and I've seen countless other articles making the same point - too many to link to here. Their advice is to diversify your anchor text, so that there is less exact match anchor text and more instances of other types, which makes sense.
However, look at the Wikipedia sample's inbound anchor text distribution:

90% of it is exact match!
In fact 4 of the pages have 100% exact match, including the one with the most links!
To clarify the chart:
- Exact: Exact match anchor text, matching the title of the page, e.g. "Mike Connelly"
- Partial (Keyword): Partial match of the page's name, e.g. "Mike Connelly bio"
- Partial (Brand): Partial match of the page's name but also including the site's name, e.g. "Carl English on Wikipedia"
- Brand: Just the site's name, e.g. "Wikipedia"
- URL: The URL of the page, e.g. "http://en.wikipedia.org/wiki/Ervil_LeBaron"
- Random: 'Click here' type anchor text and all other miscellany, e.g. "Read More", "[1]" and - my particular favourite from the sample - "Seriously crazy."
Of course, this is a small sample and therefore I might have coincidentally chosen an unusual set of pages, but then in the context of Wikipedia, it makes sense that people would link to the page with the page's title as the anchor text - especially more so than they might if naturally linking to a commercial site.
And let's not forget that it's linking to the page if it matches the page's name: for example, "NFL offensive linesman" could be considered exact match, but it doesn't align with the title of the page, while "Mike Connelly" does. I think this is what Penguin is trying to eliminate - when there's too much of an anchor text that doesn't match with the page title, URL, H-tags, etc., it's mostly certainly not deemed natural for the most part.
Dofollow/nofollow ratio
This was also an interesting one...
11 of the 15 pages' inbound links are 100% dofollow. For the other 4, it's over 94% for each of them; less than 6% nofollow. In other words, very few nofollow links.
I was always under the impression that a 'natural' backlink profile would contain more nofollow. For example, if a client came to me with a website that had a 100% dofollow inbound link profile, I'd probably recommend getting some nofollow in there, as it may seem too unnatural to be 100% dofollow! However, ultimately I guess it depends on the types of sites linking to you - e.g. blog comments are renowned for typically being nofollow (e.g. in WordPress, this applies to both the 'name' URL and any links within the body of the comment), but then how often does someone reference a Wikipedia article within a comment? I'm sure it happens, although probably not very often. Social links are also traditionally nofollow, so Wikipedia would be getting nofollow links that way, too (more on that in the next section).
I was curious to see if this was reflected domain wide, so I also checked the root domain stats: 92.85% of all links pointing to wikipedia.org as a whole are dofollow, and so 7.15% are nofollow. Slightly more nofollow than the pages I checked, suggesting that my sample just so happened to receive less nofollow links...
Social signals
9 of the pages have no social signals at all according to OSE, which records Facebook shares, Facebook 'Likes,' tweets and Google +1's.
If pages received anything, it was mainly Facebook shares. The "Ervil LeBaron" page has received an eye-opening number of social links in comparison to the other pages: 76 shares in total. The next highest received 14 and the rest each received a handful.
I certainly wouldn't consider this to be a strong indication of natural social sharing, simply because I don't think people would share Wikipedia via social platforms in the same way that they might share other information on other sites. You wouldn't necessary tweet a Wikipedia article, nor +1 one. I guess I can see people sharing Wikipedia pages on Facebook though (not that I've ever seen any of my Facebook friends doing it - ironically, I have seen someone tweet a Wikipedia page in the past, but there we go...)
Here's the full rundown:

I guess if this data tells us anything, it's that people prefer to share articles on convicted murderers than they do on various geographical locations. People for you, eh?
Conclusion / The TL;DR bit
Although not a traditional inbound link profile to analyse, Wikipedia's inbound links do highlight a number of interesting factors relating to natural links:
- Link authority is spread, but typically weighted towards the lower end of the scale, both for PA and DA, but particularly for PA. The pages I examined were heaviest in links with PA/DA scores around the 11-20 area.
- Link relevancy is apparent, although non-relevancy still appears in some cases. Relevancy doesn't seem to be exactly on topic, but is still related to the topic to some extent. Geographical relevance plays a part as well, with sites of particular countries linking to articles of buildings/landmarks/etc. within those countries.
- Overall, across the root domain, Wikipedia's inbound links are around 93% dofollow and therefore only 7% nofollow.
- A surprising 90% of anchor text is exact match, insofar as it matches the page's title/URL. However, there were still instances of varied anchor text, including partial, brand, URL and random/miscellaneous anchor text.
- Social signals are varied, and I wouldn't necessarily rely on the data (as people may not share Wikipedia on social sites in the same way they'd share other sites). Facebook sharing was the most apparent form of social sharing and - depending on the subject of a page - the amount of social shares received varied significantly.
For a site that has been negatively affected by Penguin, there could be a few lessons to be learnt here, from sites like Wikipedia. For example, Penguin might be affecting someone's site because their inbound PA/DA ratio is out of alignment with what would be considered natural, rather than anything to do with their anchor text distribution.
In fact, I'd love to see more studies of a similar nature: what about IMDb, the BBC or YouTube? In fact, for YouTube in particular, an inbound marketer running an online video campaign might want to consider analysing the most linked-to or most popular videos in their niche, or even the most linked-to video of all time. I'm sure the findings would be interesting and could even indicate what causes and encourages people to link to and share such content naturally.
[Wikipedia intro image credit: hkalant]



Comments
Please keep your comments TAGFEE by following the community etiquette
Comments are closed. Got a burning question? Head to our Q&A section to start a new conversation.