I love technical SEO (most of the time). However, it can be frustrating to come across the same site problems over and over again. In the years I've been doing SEO, I'm still surprised to see so many different websites suffering from the same issues.
This post outlines some of the most common problems I've encountered when doing site audits, along with some not-so-common ones at the end. Hopefully the solutions will help you when you come across these issues, because chances are that you will at some point!
1. Uppercase vs Lowercase URLs
From my experience, this problem is most common on websites that use
.NET. The problem stems from the fact that the server is configured to respond to URLs with uppercase letters and not to redirect or rewrite to the lowercase version.
I will admit that recently, this problem hasn't been as common as it was because generally, the search engines have gotten much better at choosing the canonical version and ignoring the duplicates. However, I've seen too many instances of search engines not always doing this properly, which means that you should make it explicit and not rely on the search engines to figure it out for themselves.
How to solve:
There is a
URL rewrite module which can help solve this problem on IIS 7 servers. The tool has a nice option within the interface that allows you to enforce lowercase URLs. If you do this, a rule will be added to the web config file which will solve the problem.
More resources for solutions:
2. Multiple versions of the homepage
Again, this is a problem I've encountered more with .NET websites, but it can happen quite easily on other platforms. If I start a site audit on a site which I know is .NET, I will almost immediately go and check if this page exists:
www.example.com/default.aspx
The verdict? It usually does! This is a duplicate of the homepage that the search engines can usually find via navigation or XML sitemaps.
Other platforms can also generate URLs like this:
www.example.com/index.html
www.example.com/home
I won't get into the minor details of how these pages are generated because the solution is quite simple. Again, modern search engines can deal with this problem, but it is still best practice to remove the issue in the first place and make it clear.
How to solve:
Finding these pages can be a bit tricky as different platforms can generate different URL structures, so the solution can be a bit of a guessing game. Instead, do a crawl of your site, export the crawl into a CSV, filter by the META title column, and search for the homepage title. You'll easily be able to find duplicates of your homepage.
I always prefer to solve this problem by adding a 301 redirect to the duplicate version of the page which points to the correct version. You can also solve the issue by using the rel=canonical tag, but I stand by a 301 redirect in most cases.
Another solution is to conduct a site crawl using a tool like
Screaming Frog to find internal links pointing to the duplicate page. You can then go in and edit the duplicate pages so they point directly to the correct URL, rather than having internal links going via a 301 and losing a bit of link equity.
Additional tip - you can usually decide if this is actually a problem by looking at the Google cache of each URL. If Google hasn't figured out the duplicate URLs are the same, you will often see different PageRank levels as well as different cache dates.
More resources for solutions:
3. Query parameters added to the end of URLs
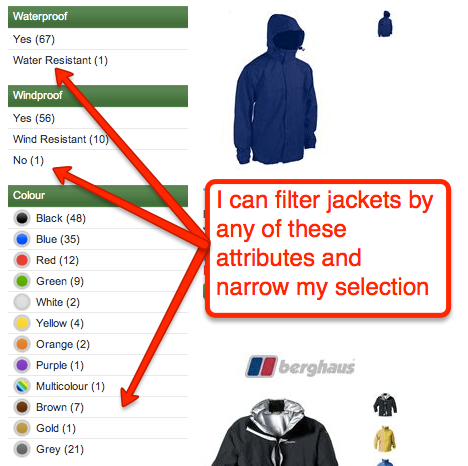
This problem tends to come up most often on eCommerce websites that are database driven. There of a chance of occurrence on any site, but the problem tends to be bigger on eCommerce websites as there are often loads of product attributes and filtering options such as colour, size, etc. Here is an example from
Go Outdoors (not a client):
In this case, the URLs users click on are relatively friendly in terms of SEO, but quite often you can end up with URLs such as this:
www.example.com/product-category?colour=12
This example would filter the product category by a certain colour. Filtering in this capacity is good for users but may not be great for search, especially if customers do not search for the specific type of product using colour. If this is the case, this URL is not a great landing page to target with certain keywords.
Another possible issue that has a tendency to use up TONS of crawl budget is when said parameters are combined together. To make things worse, sometimes the parameters can be combined in different orders but will return the same content. For example:
www.example.com/product-category?colour=12&size=5
www.example.com/product-category?size=5&colour=12
Both of these URLs would return the same content but because the paths are different, the pages could be interpreted as duplicate content.
I worked on a client website a couple of years back who had this issue. We worked out that with all the filtering options they had, there were over a BILLION URLs that could be crawled by Google. This number was off the charts when you consider that there were only about 20,000 products offered.
Remember, Google does allocate crawl budget based on your PageRank. You need to ensure that this budget is being used in the most efficient way possible.
How to solve:
Before going further, I want to address another common, related problem: the URLs may not be SEO friendly because they are not database driven. This isn't the issue I'm concerned about in this particular scenario as I'm more concerned about wasted crawl budget and having pages indexed which do not need to be, but it is still relevant.
The first place to start is addressing which pages you want to allow Google to crawl and index. This decision should be driven by your keyword research, and you need to cross reference all database attributes with your core target keywords. Let's continue with the theme from Go Outdoors for our example:
Here are our core keywords:
-
Waterproof jackets
-
Hiking boots
-
Women's walking trousers
On an eCommerce website, each of these products will have attributes associated with them which will be part of the database. Some common examples include:
-
Size (i.e. Large)
-
Colour (i.e. Black)
-
Price (i.e. £49.99)
-
Brand (i.e. North Face)
Your job is to find out which of these attributes are part of the keywords used to find the products. You also need to determine what combination (if any) of these attributes are used by your audience.
In doing so, you may find that there is a high search volume for keywords that include "North Face" + "waterproof jackets." This means that you will want a landing page for "North Face waterproof jackets" to be crawlable and indexable. You may also want to make sure that the database attribute has an SEO friendly URL, so rather than "waterproof-jackets/?brand=5" you will choose "waterproof-jackets/north-face/." You also want to make sure that these URLs are part of the navigation structure of your website to ensure a good flow of PageRank so that users can find these pages easily.
On the other hand, you may find that there is not much search volume for keywords that combine "North Face" with "Black" (for example, "black North Face jackets"). This means that you probably do not want the page with these two attributes to be crawlable and indexable.
Once you have a clear picture of which attributes you want indexed and which you don't, it is time for the next step, which is dependant on whether the URLs are already indexed or not.
If the URLs are not already indexed, the simplest step to take is to add the URL structure to your robots.txt file. You may need to play around with some Regex to achieve this. Make sure you test your regex properly so you don't block anything by accident. Also, be sure to use the
Fetch as Google feature in Webmaster Tools. It's important to note that if the URLs are already indexed, adding them to your robots.txt file will NOT get them out of the index.
If the URLs are indexed, I'm afraid you need to use a plaster to fix the problem: the rel=canonical tag. In many cases, you are not fortunate enough to work on a website when it is being developed. The result is that you may inherit a situation like the one above and not be able to fix the core problem. In cases such as this, the rel=canonical tag serves as a plaster put over the issue with the hope that you can fix it properly later. You'll want to add the rel=canonical tag to the URLs you do not want indexed and point to the most relevant URL which you do want indexed.
More resources for solutions:
4. Soft 404 errors
This happens more often than you'd expect. A user will not notice anything different, but search engine crawlers sure do.
A
soft 404 is a page that looks like a 404 but returns a HTTP status code 200. In this instance, the user sees some text along the lines of "Sorry the page you requested cannot be found." But behind the scenes, a code 200 is telling search engines that the page is working correctly. This disconnect can cause problems with pages being crawled and indexed when you do not want them to be.
A soft 404 also means you cannot spot real broken pages and identify areas of your website where users are receiving a bad experience. From a link building perspective (I had to mention it somewhere!), neither solution is a good option. You may have incoming links to broken URLs, but the links will be hard to track down and redirect to the correct page.
How to solve:
Fortunately, this is a relatively simply fix for a developer who can set the page to return a 404 status code instead of a 200. Whilst you're there, you can have some fun and make a cool 404 page for your user's enjoyment. Here are
some examples of awesome 404 pages, and I have to point to Distilled's
own page here :)
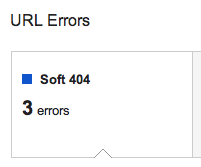
To find soft 404s, you can use the feature in Google Webmaster Tools which will tell you about the ones Google has detected:
You can also perform a manual check by going to a broken URL on your site (such as
www.example.com/5435fdfdfd) and seeing what status code you get. A tool I really like for checking the status code is
Web Sniffer, or you can use the
Ayima tool if you use Google Chrome.
More resources for solutions:
5. 302 redirects instead of 301 redirects
Again, this is an easy redirect for developers to get wrong because, from a user's perspective, they can't tell the difference. However, the search engines treat these redirects very differently. Just to recap, a 301 redirect is permanent and the search engines will treat it as such; they'll pass link equity across to the new page. A 302 redirect is a temporary redirect and the search engines will not pass link equity because they expect the original page to come back at some point.
How to solve:
To find 302 redirected URLs, I recommend using a deep crawler such as
Screaming Frog or the
IIS SEO Toolkit. You can then filter by 302s and check to see if they should really be 302s, or if they should be 301s instead.
To fix the problem, you will need to ask your developers to change the rule so that a 301 redirect is used rather than a 302 redirect.
More resources for solutions:
6. Broken/Outdated sitemaps
Whilst not essential, XML sitemaps are very useful to the search engines to make sure they can find all URLs that you care about. They can give the search engines a nudge in the right direction. Unfortunately, some XML sitemaps are generated one-time-only and quickly become outdated, causing them to contain broken links and not contain new URLs.
Ideally, your XML sitemaps should be updated regularly so that broken URLs are removed and new URLs are added. This is more important if you're a large website that adds new pages all the time. Bing
has also said that they have a threshold for "dirt" in a sitemap and if the threshold is hit, they will not trust it as much.
How to solve:
First, you should do an audit of your current sitemap to find broken links.
This great tool from Mike King can do the job.
Second, you should speak to your developers about making your XML sitemap dynamic so that it updates regularly. Depending on your resources, this could be once a day, once a week, or once a month. There will be some development time required here, but it will save you (and them) plenty of time in the long run.
An extra tip here: you can experiment and create sitemaps which only contain new products and have these particular sitemaps update more regularly than your standard sitemaps. You could also do a bit of extra-lifting if you have dev resources to create a sitemap which only contains URLs which are not indexed.
More resources for solutions:
A few uncommon technical problems
I want to include a few problems that are not common and can actually be tricky to spot. The issues I'll share have all been seen recently on my client projects.
7. Ordering your robots.txt file wrong
I came across an example of this very recently, which led to a number of pages being crawled and indexed which were blocked in robots.txt.
The reason that the URLs in this case were crawled was because the commands within the robots.txt file was wrong. Individually the commands were correct, but they didn't work together correctly.
Google explicitly say this in their
guidelines but I have to be honest, I hadn't really come across this problem before so it was a bit of a surprise.
How to solve:
Use your robots commands carefully and if you have separate commands for Googlebot, make sure you also tell Googlebot what other commands to follow - even if they have already been mentioned in the catchall command. Make use of the testing feature in Google Webmaster Tools that allows you to test how Google will react to your robots.txt file.
8. Invisible character in robots.txt
I recently did a technical audit for one of my clients and noticed a warning in Google Webmaster Tools stating that "Syntax was not understood" on one of the lines. When I viewed the file and tested it, everything looked fine. I showed the issue to
Tom Anthony who fetched the file via the command line and he diagnosed the problem: an invisible character had somehow found it's way into the file.
I managed to look rather silly at this point by re-opening the file and looking for it!
How to solve:
The fix is quite simple. Simply rewrite the robots.txt file and run it through the command line again to re-check. If you're unfamiliar with the command line, check out this post by
Craig Bradford over at Distilled.
9. Google crawling base64 URLs
This problem was a very interesting one we recently came across, and another one that Tom spotted. One of our clients saw a massive increase in the number of 404 errors being reported in Webmaster Tools. We went in to take a look and found that nearly all of the errors were being generated by URLs in this format:
/aWYgeW91IGhhdmUgZGVjb2RlZA0KdGhpcyB5b3Ugc2hvdWxkIGRlZmluaXRlbHkNCmdldCBhIGxpZmU=/
Webmaster tools will tell you where these 404s are linked from, so we went to the page to findout how this URL was being generarted. As hard as we tried, we couldn't find it. After lots of digging, we were able to see that these were authentication tokens generated by Ruby on Rails to try and prevent cross site requests. There were a few in the code of the page, and Google were trying to crawl them!
In addition to the main, problem, the authentication tokens are all generated on the fly and are unique, hence why we couldn't find the ones that Google were telling us about.
How to solve:
In this case, we were quite lucky because we were able to add some Regex to the robots.txt file which told Google to stop crawling these URLs. It took a bit of time for Webmaster Tools to settle down, but eventually everything was calm.
10. Misconfigured servers
This issue is actually written by Tom, who worked on this particular client project. We encountered a problem with a website's main landing/login page not ranking. The page had been ranking and at some point had dropped out, and the client was at a loss. The pages all looked fine, loaded fine, and didn't seem to be doing any cloaking as far as we could see.
After lots of investigation and digging, it turned out that there was a subtle problem caused by a mis-configuration of the server software, with the HTTP headers from their server.
Normally an 'Accept' header would be sent by a client (your browser) to state which file types it understands, and very rarely this would modify what the server does. The server when it sends a file always sends a "Content-Type" header to specify if the file is HTML/PDF/JPEG/something else.
Their server (they're using Nginx) was returning a "Content-Type" that was a mirror of the first fiel type found in the clients "Accept" header. If you sent an accept header that started "text/html," then that is what the server would send back as the content-type header. This is peculiar behaviour, but it wasn't being noticed because browsers almost always send "text/html" as the start of their Accept header.
However, Googlebot sends "Accept: */*" when it is crawling (meaning it accepts anything).
(See: http://webcache.googleusercontent.com/search?sourceid=chrome&ie=UTF-8&q=cache:http://www.ericgiguere.com/tools/http-header-viewer.html)
I found if I sent a */* header this caused the server to fall down as */* is not a valid content-type and the server would crumble and send an error response.
Changing your browsers user agent to Googlebot does not influence the HTTP headers, and tools such as web-sniffer also don't send the same HTTP headers as Googlebot, so you would never notice this issue with them!
Within a few days of fixing the issue, the pages were re-indexed and the client saw a spike in revenue.






Comments
Please keep your comments TAGFEE by following the community etiquette
Comments are closed. Got a burning question? Head to our Q&A section to start a new conversation.