

Find Your Site's Biggest Technical Flaws in 60 Minutes
The author's views are entirely their own (excluding the unlikely event of hypnosis) and may not always reflect the views of Moz.
I've deliberately put myself in some hot water to demonstrate how I would do a technical SEO site audit in 1 hour to look for quick fixes, (and I've actually timed myself just to make it harder). For the pros out there, here's a look into a fellow SEO 's workflow; for the aspiring, here's a base set of checks you can do quickly.
I've got some lovely volunteers who have kindly allowed me to audit their sites to show you what can be done in as little as 60 minutes.
I'm specifically going to look for crawling, indexing and potential Panda threatening issues like:
- Architecture (unnecessary redirection, orphaned pages, nofollow)
- Indexing & Crawling (canonical, noindex, follow, nofollow, redirects, robots.txt, server errors)
- Duplicate content & On page SEO (repeated text, pagination, parameter based, dupe/missing titles, h1s, etc..)
Don't worry if you're not technical, most of the tools and methods I'm going to use are very well documented around the web.
Let's meet our volunteers!
Here's what I'll be using to do this job:
- SEOmoz toolbar - Make sure highlight nofollow links is turned on - so you can visibly diagnose crawl path restrictions
- Screaming Frog Crawler - Full website crawl with Screaming Frog (User agent set to Googlebot) - Full user guide here
- Chrome, and Firefox (FF will have Javascript, CSS disabled and User Agent as Googlebot) - To look for usability problems caused by CSS or Javascript
- Google search queries - to check the index for issues like content duplication, dupe subdomains, penalties etc..
Here are other checks I've done, but left out in the interest of keeping it short:
- Open Site Explorer - Download a back link report to see if you're missing out on links pointing to orphaned, 302 or incorrect URLs on your site. If you find people linking incorrectly, add some 301 rules on your site to harness that link juice
- http://www.tomanthony.co.uk/tools/bulk-http-header-compare/ - Check if the site is redirecting Googlebot specifically
- http://spyonweb.com/ - Any other domains connected you should know about? Mainly for duplicate content
- http://builtwith.com/ - Find out if the site is using Apache, IIS, PHP and you'll know which vulnerabilities to look for automatically
- Check for hidden text, CSS display:none funniness, robots.txt blocked external JS files, hacked / orphaned pages
My essential reports before I dive in:
- Full website crawl with Screaming Frog (User agent set to Googlebot)
- A report of everything in Google's index using the site: (1000 results per query unfortunately - this is how I do it)
Down to business...
Architecture Issues
1) Important broken links
We'll always have broken links here and there, and in an ideal world they would all work. Just make sure for SEO & usability that important links (homepage) are always in good shape. The following broken link is on webrevolve homepage that should be pointing to their blog, but returns a 404. This is an important link because it's a great feature and I definitely do want to read more of their content.
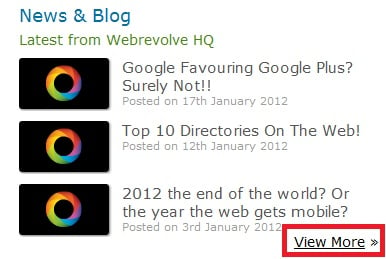
Fix: Get in there and point that link to the correct page which is http://www.webrevolve.com/our-blog/
How did I find it: Screaming Frog > response codes report
2) Unnecessary Redirection
This happens a lot more than people like to believe. The problem is that when we 301 a page to a new home we often forget to correct the internal links pointing to the old page (the one with the 301 redirect).
This page http://www.lexingtonlaw.com/credit-education/foreclosure.html 301 redirects to http://www.lexingtonlaw.com/credit-education/foreclosure-2.html
However, they still have internal links pointing to the old page.
- http://www.lexingtonlaw.com/credit-education/bankruptcy.html?linkid=bankruptcy
- http://www.lexingtonlaw.com/blog/category/credit-repair/page/10
- http://www.lexingtonlaw.com/credit-education/bankruptcy.html?select_state=1&linkid=selectstate
- http://www.lexingtonlaw.com/credit-education/collections.html
Fix: Get in that CMS and change the internal links to point to http://www.lexingtonlaw.com/credit-education/foreclosure-2.html
How did I find it: Screaming Frog > response codes report
3) Multiple subdomains - Canonicalizing the www or non-www version
One of the first basic principles of SEO, and there are still tons of legacy sites that are tragically splitting their link authority by not using redirecting the www to non-www or vice versa.
Sorry to pick on you CVSports :S
- http://cvcsports.com/
- http://www.cvcsports.com/
Oh, and a couple more have got their way into Google's index that you should remove too:
- http://smtp.cvcsports.com/
- http://pop.cvcsports.com/
- http://mx1.cvcsports.com/
- http://ww.cvcsports.com/
- http://www.buildyourjacket.com/
- http://buildyourjacket.com/
Basically, you have 7 copies of your site in the index..
Fix: I recommend using www.cvcsports.com as the main page, and you should use your htaccess file to create 301 redirects for all of these subdomains to the main www site.
How did I find it? Google query "site:cvcsports.com -www" (I also set my results number to 100 for check through the index quicker)
4) Keeping URL structure consistent
It's important to note that this only becomes a problem when external links are pointing to the wrong URLs. *Almost* every back link is precious, and we want to ensure that we get maximum value from each one. Except we can control how we get linked to; without www, with capitals, or trailing slashes for example. Short of contacting the webmaster to change it, we can always employ 301 redirects to harness as much value as possible. The one place this shouldn't happen is on your own site.
We all know that www.example.com/CAPITALS is different to www.example.com/captials when it comes to external link juice. As good SEOs we typically combat human error by having permanent redirect rules to enforce only one version of a URL (ex. forcing lowercase), which may cause unnecessary redirects if someone links in contradiction to redirects.
Here are some examples from our sites:
- http://www.lexingtonlaw.com/credit-education/rebuild-credit 301's to trailing slash version
- http://webrevolve.com/web-design-development/conversion-rate-optimisation/ Redirects to the www version
Fix: Determine your URL structure, should they all have trailing slashes, www, lowercase? Whatever you decide, be consistent and you can avoid future problems. Crawl your site, and fix these
Indexing & Crawling
1) Check for Penalties
None of our volunteers have any immediately noticeable penalties, so we can just move on. This is a 2 second check that you must do before trying to nitpick at other issues.
How did I do it? Google search queries for exact homepage URL and brand name. If it doesn't show up, you'll have to investigate further.
2) Canonical, noindex, follow, nofollow, robots.txt
I always do this so I understand how clued up SEO-wise the developers are, and to gain more insight into the site. You wouldn't check for these tags in detail unless you had just cause (ex. A page that should be ranking isn't
I'm going to combine this section as it requires much more than just a quick look, especially on bigger sites. First and foremost check robots.txt and look through some of the blocked directories, try and determine why they are being blocked and which bots they are blocking them from. Next, get Screaming Frog in the mix as it's internal crawl report will automatically check each URL for Meta Data (noindex, header level nofollow & follow) and give you the canonical URL if there happens to be one.
If you're spot checking a site, the first thing you should do is understand what tags are in use and why they're using them.
Take Webrevolve for instance, they've chosen to NOINDEX,FOLLOW all of their blog author pages.
- http://www.webrevolve.com/author/tom/
- http://www.webrevolve.com/author/paul/
This is a guess but I think these pages don't provide much value, and are generally not worth seeing in search results. If these were valuable, traffic driving pages, I would suggest they remove NOINDEX but in this case I believe they've made the right choice.
They also implement self-serving canonical tags (yes I just made that up), basically each page will have a canonical tag that points to itself. I generally have no problem with this practice as it usually makes it easier for developers.
Example: http://www.webrevolve.com/our-work/websites/ecommerce/
3) Number of pages VS Number of pages indexed by Google
What we really want to know here is how many pages Google has indexed. There's 2 ways of doing this, using Google Webmaster Tools by submitting a sitemap you'll get stats back on how many URLs are actually in the index.
OR you can do it without having access but it's much less efficient. This is how I would check...
- Run a Screaming Frog Crawl (make sure you obey robots.txt)
- Do a site: query
- Get the *almost never accurate* results number and compare them to total pages in crawl
If the numbers aren't close, like CVCSports (206 pages vs 469 in the index) you probably want to look into it further.
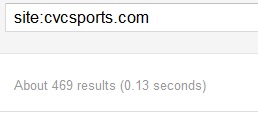
I can tell you right now that CVCSports has 206 pages (not counting those that have been blocked by robots.txt). Just by doing this quickly I can tell there's something funny going on and I need to look deeper.
Just to cut to the chase, CVCsports has multiple copies of the domain on subdomains which is causing this.
Fix: It varies. You could have complicated problems, or it might just be as easy as using canonical, noindex, or 301 redirects. Don't be tempted to block the unwanted pages by robots.txt as this will not remove pages from the index, and will only prevent these pages from being crawled.
Duplicate Content & On Page SEO
Google's Panda update was definitely a game changer, and it caused massive losses for some sites. One of the easiest ways of avoiding at least part of Panda's destructive path is to avoid all duplicate content on your site.
1) Parameter based duplication
URL parameters like search= or keyword= often cause duplication unintentionally. Here's some examples:
- http://www.lexingtonlaw.com/credit-repair-news/economic-and-credit-trends/mortgage-lenders-rejecting-more-applications.html
- http://www.lexingtonlaw.com/credit-repair-news/economic-and-credit-trends/mortgage-lenders-rejecting-more-applications.html?select_state=1&linkid=selectstate
- http://www.lexingtonlaw.com/credit-repair-news/credit-report-news/california-ruling-sets-off-credit-fraud-concerns.html
- http://www.lexingtonlaw.com/credit-repair-news/credit-report-news/california-ruling-sets-off-credit-fraud-concerns.html?select_state=1&linkid=selectstate
- http://www.lexingtonlaw.com/credit-repair-news/economic-and-credit-trends/one-third-dont-save-for-christmas.html
- http://www.lexingtonlaw.com/credit-repair-news/economic-and-credit-trends/one-third-dont-save-for-christmas.html?select_state=1&linkid=selectstate
- http://www.lexingtonlaw.com/credit-repair-news/economic-and-credit-trends/financial-issues-driving-many-families-to-double-triple-up.html
- http://www.lexingtonlaw.com/credit-repair-news/economic-and-credit-trends/financial-issues-driving-many-families-to-double-triple-up.html?select_state=1&linkid=selectstate
Fix: Again, it varies. If I was giving general advice I would say use clean links in the first place - depending on the complexity of the site you might consider 301s, canonical tags or even NOINDEX. Either way, just get rid of them !
How did I find it? Screaming Frog > Internal Crawl > Hash tag column
Basically, Screaming Frog will create a unique hexadecimal number based on source code. If you have matching hash tags, you have duplicate source code (exact dupe content). Once you have your crawl ready, use excel to filter it out (complete instructions here).
2) Duplicate Text content
Having the same text on multiple pages shouldn't be a crime, but post Panda it's better to avoid it completely. I hate to disappoint here, but there's no exact science to finding duplicate text content.
Sorry CVCSports, you're up again ;)
http://www.copyscape.com/?q=http%3A%2F%2Fwwww.cvcsports.com%2F
Don't worry, we've already addressed your issues above, just use 301 redirects to get rid of these copies
Fix: Write unique content as much as possible. Or be cheap and stick it in an image, that works too.
How did I find it? I used http://www.copyscape.com, but you can also copy & paste text into Google search
3) Duplication caused by pagination
Page 1, Page 2, Page 3... You get the picture. Over time, sites can accumulate thousands if not millions of duplicate pages because of those nifty page links. I swear I've seen a site with 300 pages for one product page.
Our examples:
- http://cvcsports.com/blog?page=1
- http://cvcsports.com/blog?page=2
Another example?
- http://www.lexingtonlaw.com/blog/page/23
- http://www.lexingtonlaw.com/blog/page/22
Fix: General advice is to use the NOINDEX, FOLLOW directive. (This tells Google not to add this page to the index, but crawl through the page). An alternative might be to use the canonical tag but this all depends on the reason why pagination exists. For example, if you had a story that was separated across 3 pages, you definitely would want them all indexed. However, these example pages are pretty thin and *could* be considered as low quality for Google.
How did I find it? Screaming Frog > Internal links > Check for pagination parameters
Open up the pages and you'll quickly determine if they are auto generated, thin pages. Once you know the pagination parameter or structure of the URL you can check Google's index like so: site:example.com inurl:page=
Time's up! There's so much more I wish I could do, but I was strict about the 1 hour time limit. A big thank you to the brave volunteers who put their sites forward for this post. There was one site that just didn't make the cut, mainly because they've done a great job technically, and, um, I couldn't find any technical faults.
Now it's time for the community to take some shots at me!
- How did I do?
- What could I have done better?
- Any super awesome tools I forgot?
- Any additional tips for the volunteer sites?
Thanks for reading, you can reach me on Twitter @dsottimano if want to chat and share your secrets ;)



Comments
Please keep your comments TAGFEE by following the community etiquette
Comments are closed. Got a burning question? Head to our Q&A section to start a new conversation.