

Just How Smart Are Search Robots?
The author's views are entirely their own (excluding the unlikely event of hypnosis) and may not always reflect the views of Moz.
Matt Cutts announced at Pubcon that Googlebot is “getting smarter.” He also announced that Googlebot can crawl AJAX to retrieve Facebook comments coincidentally only hours after I unveiled Joshua Giardino's research that suggested Googlebot is actually a headless browser based off the Chromium codebase at SearchLove New York. I'm going to challenge Matt Cutts' statements, Googlebot hasn't just recently gotten smarter, it actually hasn’t been a text-based crawler for some time now; nor has BingBot or Slurp for that matter. There is evidence that Search Robots are headless web browsers and the Search Engines have had this capability since 2004.
Disclaimer: I do not work for any Search Engine. These ideas are speculative based on patent research done by Joshua Giardino, myself, some direction from Bill Slawski and what can be observed on Search Engine Results Pages.

A headless browser is simply a full-featured web browser with no visual interface. Similar to the TSR (Terminate Stay Resident) programs that live on your system tray in Windows they run without you seeing anything on your screen but other programs may interact with them. With a headless browser you can interface with it via a command-line or scripting language and therefore load a webpage and programmatically examine the same output a user would see in Firefox, Chrome or (gasp) Internet Explorer. Vanessa Fox alluded that Google may be using these to crawl AJAX in January of 2010.
However Search Engines would have us believe that their crawlers are still similar to Unix’s Lynx browser and can only see and understand text and its associated markup. Basically they have trained us to believe that Googlebot, Slurp and Bingbot are a lot like Pacman in that you point it in a direction and it gobbles up everything it can without being able to see where it’s going or what it’s looking at. Think of the dashes that Pacman eats as webpages. Every once in a while it hits a wall and is forced in another direction. Think of SEOs as the power pills. Think of ghosts as technical SEO issues that might trip up Pacman and cause him to not complete the level that is your page. When an SEO gets involved with a site it helps a search engine spider eat the ghost; when they don’t Pacman dies and starts another life on another site.
.jpg)
That’s what they have been selling us for years the only problem is it’s simply not true anymore and hasn’t been for some time. To be fair though Google normally only lies by omission so it’s our fault for taking so long to figure it out.
I encourage you to read Josh’s paper in full but some highlights that indicate this are:
-
A patent filed in 2004 entitled “Document Segmentation Based on Visual Gaps” discusses methods Google uses to render pages visually and traversing the Document Object Model (DOM) to better understand the content and structure of a page. A key excerpt from that patent says “Other techniques for generating appropriate weights may also be used, such as based on examination of the behavior or source code of Web browser software or using a labeled corpus of hand-segmented web pages to automatically set weights through a machine learning process.”
-
The wily Mr. Cutts suggested at Pubcon that GoogleBot will soon be taking into account what is happening above the fold as an indication user experience quality as though it were a new feature. That’s curious because according to the “Ranking Documents Based on User Behavior and/or Feature Data” patent from June 17, 2004 they have been able to do this for the past seven years. A key excerpt from that patent describes “Examples of features associated with a link might include the font size of the anchor text associated with the link; the position of the link (measured, for example, in a HTML list, in running text, above or below the first screenful viewed on an 800.times.600 browser display, side (top, bottom, left, right) of document, in a footer, in a sidebar, etc.); if the link is in a list, the position of the link in the list; font color and/or attributes of the link (e.g., italics, gray, same color as background, etc.);” This is evidence that Google has visually considered the fold for some time. I also would say that this is live right now as there are instant previews that show a cut-off at the point which Google is considering the fold.
- It is no secret that Google has been executing JavaScript to a degree for some time now but “Searching Through Content Which is Accessible Through Web-based Forms” shows an indication that Google is using a headless browser to perform the transformations necessary to dynamically input forms. “Many web sites often use JavaScript to modify the method invocation string before form submission. This is done to prevent each crawling of their web forms. These web forms cannot be automatically invoked easily. In various embodiments, to get around this impediment, a JavaScript emulation engine is used. In one implementation, a simple browser client is invoked, which in turn invokes a JavaScript engine.” Hmmm…interesting.
Google also owns a considerable amount of IBM patents as of June and August of 2011 and with that comes a lot of their awesome research into remote systems, parallel computing and headless machines for example the “Simultaneous network configuration of multiple headless machines” patent. Though Google has clearly done extensive research of their own in these areas.
Not to be left out there’s a Microsoft patent entitled “High Performance Script Behavior Detection Through Browser Shimming” where there is not much room for interpretation; in so many words it says Bingbot is a browser. "A method for analyzing one or more scripts contained within a document to determine if the scripts perform one or more predefined functions, the method comprising the steps of: identifying, from the one or more scripts, one or more scripts relevant to the one or more predefined functions; interpreting the one or more relevant scripts; intercepting an external function call from the one or more relevant scripts while the one or more relevant scripts are being interpreted, the external function call directed to a document object model of the document; providing a generic response, independent of the document object model, to the external function call; requesting a browser to construct the document object model if the generic response did not enable further operation of the relevant scripts; and providing a specific response, obtained with reference to the constructed document object model, to the external function call if the browser was requested to construct the document object model."(emphasis mine) Curious, indeed.
Furthermore, Yahoo filed a patent on Feb 22, 2005 entitled "Techniques for crawling dynamic web content" which says "The software system architecture in which embodiments of the invention are implemented may vary. FIG 1 is one example of an architecture in which plug-in modules are integrated with a conventional web crawler and a browser engine which, in one implementation, functions like a conventional web browser without a user interface (also referred to as a "headless browser")." Ladies and gentlemen I believe they call that a "smoking gun." The patent then goes on to discuss automatic and custom form filling and methods for handling JavaScript.
.jpg)
Search Engine crawlers are indeed like Pacman but not the floating mouth without a face that my parents jerked across the screen of arcades and bars in the mid-80’s. Googlebot and Bingbot are actually more like the ray-traced Pacman with eyes, nose and appendages that we’ve continued to ignore on console systems since the 90’s. This Pacman can punch, kick, jump and navigate the web with lightning speed in 4 dimensions (the 4th is time – see the freshness update). That is to say Search Engine crawlers can render the page as we see them in our own web browsers and have achieved such a high level of programmatic understanding that allows them to emulate a user.
Have you ever read the EULA for Chrome? Yeah me neither, but as with most Google products they ask you to opt-in to a program in which your usage data is sent back to Google. I would surmise that this usage data is not just used to inform the ranking algorithm (slightly) but that it is also used as a means to train Googlebot’s machine learning algorithms in order to teach it to input certain fields in forms. For example Google can use user form inputs to figure out what type of data goes into which field and then programmatically fill forms with generic data of that type. If 500 users put in an age in a form field named “age” it has a valid data set that tells it to input an age. Therefore Pacman no longer runs into doors and walls, he has keys and can scale the face of buildings.

-
Instant Previews - This is why you’re seeing annotated screenshots in Instant Previews of the SERPs. The instant previews are in fact an impressive feat in that they not only take a screenshot of a page but they also visually highlight and extract text pertinent to your search query. This simply cannot be accomplished with a text-based crawler.
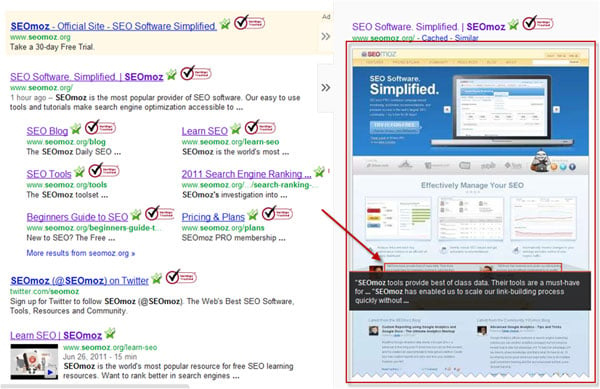
-
Flash Screenshots - You may have also noticed in Google Webmaster Tools screenshots of Flash sites. Wait I thought Google couldn’t see Flash?
-
AJAX POST Requests Confirmed - Matt Cutts also confirmed that GoogleBot can in fact handle AJAX POST requests coincidentally a matter of hours after the “Googlebot Is Chrome” article was tweeted by Rand, it made its way to the front of HackerNews and brought my site down. By definition AJAX is content loaded by JavaScript when an action takes place after a page is loaded. Therefore it cannot be crawled with a text-based crawler because a text-based crawler does not execute JavaScript it only pulls down existing code as it is rendered at the initial load.
-
Google Crawling Flash - Mat Clayton also showed me some server logs where GoogleBot has been accessing URLs that are only accessible via embedded in Flash modules on Mixcloud.com:
66.249.71.130 "13/Nov/2011:11:55:41 +0000" "GET /config/?w=300&h=300&js=1&embed_type=widget_standard&feed=http%3A//www.mixcloud.com/chrisreadsubstance/bbe-mixtape-competition-2010.json&tk=TlVMTA HTTP/1.1" 200 695 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
66.249.71.116 "13/Nov/2011:11:51:14 +0000" "GET /config/?w=300&h=300&js=1&feed=http%3A//www.mixcloud.com/ZiMoN/electro-house-mix-16.json&embed_type=widget_standard&tk=TlVMTA HTTP/1.1" 200 694 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
Granted this is not new, but another post from 2008 explains that Google "explores Flash files in the same way that a person would, by clicking buttons, entering input, and so on." Oh, you mean like a person would with a browser?
- Site Speed – Although Google could potentially get site load times from toolbars and usage data from Chrome it’s far more dependable for them to get it by crawling the web themselves. Without actually executing all the code on a page it’s not realistic that the calculation of page load time would be accurate.
So far this might sound like Googlebot is only a few steps from SkyNet and due to years of SEOs and Google telling us their search crawler is text-based it might sound like science fiction to you. I assure you that it’s not and that a lot of the things I’m talking about can be easily accomplished by programmers far short of the elite engineering team at Google.

PhantomJS is a headless Webkit browser that can be controlled via a JavaScript API. With a little bit of script automation a browser can easily be turned into a web crawler. Ironically the logo is a ghost similar to the ones in Pacman and the concept is quite simple really; PhantomJS is used to load a webpage as a user sees it in Firefox, Chrome or Safari, extract features and follow the links. PhantomJS has infinite applications for scraping and otherwise analyzing sites and I encourage the SEO community to embrace it as we move forward.
Josh has used PhantomJS to prepare some proof of concepts that I shared at SearchLove.
I had mentioned before when I released GoFish that I’d had trouble scraping the breakout terms from Google Insights using a text-based crawler due to the fact that it’s rendered using AJAX. Richard Baxter suggested that it was easily scrapable using an XPath string which leads me to believe that the ImportXML crawling architecture in Google Docs is based on a headless browser as well.
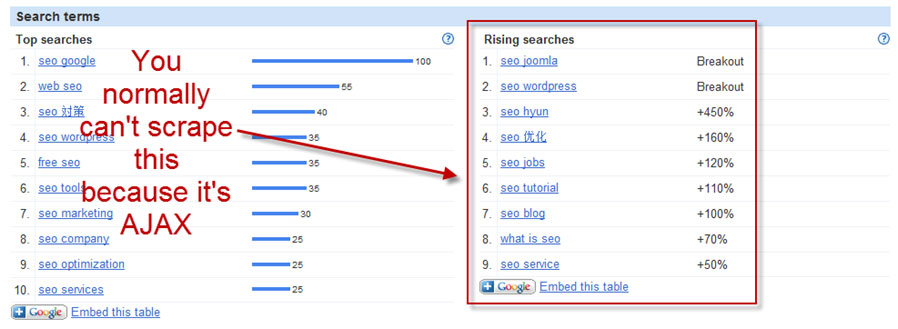
In any event here Josh pulls the breakout terms from the page using PhantomJS:
Creating screenshots with a text-based crawler is impossible but with a headless webkit browser it’s a piece of cake. Here’s an example that Josh has prepared to show screenshots being created programmatically using PhantomJS.
Chromium is Google’s open source fork of the Webkit browser and I seriously doubt that Google’s motives for building a browser were altruistic. The aforementioned research would suggest that GoogleBot is a multi-threaded headless browser based on that same code.


Well actually they do but they say the "instant preview crawler" is a completely separate entity. Think of the Instant Crawler as Ms. Pacman.
A poster on Webmaster Central complained that they were seeing "Mozilla/5.0 (X11; U; Linux x86_64; en-US) AppleWebKit/534.14 (KHTML, like Gecko) Chrome/9.0.597 Safari/534.14" rather than "Mozilla/5.0 (en-us) AppleWebKit/525.13 (KHTML, like Gecko; Google Web Preview) Version/3.1 Safari/525.13" as the Google Web Preview user agent in their logs.
John Mu reveals "We use the Chrome-type user-agent for the Instant Previews testing tool, so that we're able to compare what a browser (using that user-agent) would see with what we see through Googlebot accesses for the cached preview image."
While the headless browser and Googlebot as we know it may be separate in semantic explanation I believe that they always crawl in parallel and inform indexation and ultimately rankings. In other words it's like a 2-player simultaneous version of Pacman with a 3D Ms. Pacman and a regular Pacman playing the same levels at the same time. After all it wouldn't make sense for the crawlers to crawl the whole web twice independently.
So why aren't they more transparent about these capabilities as they pertain to rankings? Two Words: Search Quality. As long as Search Engines can hide behind the deficiencies of a text-based crawler they can continue to use it as a scapegoat for their inability to serve up the best results. They can continue to move towards things such as the speculated AuthorRank and lean on SEOs to literally optimize their Search Engines. They can continue to say vague things like “don’t chase the algorithm”, “improve your user experience” and “we’re weighing things above the fold” that force SEOs to scramble and make Google’s job easier.
Google’s primary product (and only product if you’re talking to Eric Schmidt in court) is Search and if it is publicly revealed that their capabilities are far beyond what they advertise they would then be responsible for a higher level of search quality if not indexation of impossible rich media like Flash.
In short they don’t tell us because with great power comes great responsibility.

A lot of people have asked me as Josh and I've led up to unveiling this research “what is the actionable insight?” and “how does it change what I do as far as SEO?” There are really three things as far as I’m concerned:
-
You're not Hiding Anything with Javascript - Any content you thought you were hiding with post-load JavaScript -- stop it. Bait and switching is now 100% ineffective. Pacman sees all.
-
User Experience is Incredibly Important - Google can literally see your site now! As Matt Cutts said they are looking at what's above the fold and therefore they can consider how many ads are rendered on the page in determining rankings. Google can leverage usage data in concert with the design of the site as a proxy to determine out how useful a site is to people. That's both exciting and terrifying but it also means every SEO needs to pick up a copy of "Don't Make Me Think" if they haven't already.
- SEO Tools Must Get Smarter - Most SEO tools are built on text-based scrapers and while many are quite sophisticated (SEOmoz clearly is leading the pack right now) they are still very much the 80’s Pacman. If we are to understand what Google is truly considering when ranking pages we must include more aspects in our own analyses.
-
When discussing things such as Page Authority and the likelihood of spam we should be visually examining pages programmatically rather than just limiting ourselves to the metrics like keyword density and the link graph. In other words we need a UX Quality Score that is influenced by visual analysis and potential spammy transformations.
-
We should be comparing how much the rendered page differs from what would otherwise be expected of the code. We could call this a Delta Score.
-
When measuring the distribution of link equity from a page the dynamic transformations must also be taken into account as Search Engines are able to understand how many links are truly on a page. This could also be included within the Delta Score.
- On another note Natural Language Processing should also be included in our analyses as it is presumably a large part of what makes Google’s algo tick. This is not so much for scoring but for identifying the key concepts that a machine will associate with a given piece of content and truly understanding what a link is worth in context of what you are trying to rank for. In other words we need contextual analysis of the link graph.
There are two things that I will agree with Matt Cutts on. The only constant is change and we must stop chasing the algorithm. However we must also realize that Google will continue to feed us misinformation about their capabilities or dangle enough to make us jump to conclusions and hold on to them. Therefore we must also hold them accountable for their technology. Simply put if they can definitively prove they are not doing any of this stuff – then at this point they should be; after all these are some of the most talented engineers in the universe.
Google continues to make Search Marketing more challenging and revoke the data that allows us to build better user experiences but the simple fact is that our relationship is symbiotic. Search Engines need SEOs and Webmasters to make the web faster, easier for them to understand and we need Search Engines to react to and reward quality content by making it visible. The issue is that Google holds all the cards and I’m happy to have done my part to pull one.
Your move Matt.



Comments
Please keep your comments TAGFEE by following the community etiquette
Comments are closed. Got a burning question? Head to our Q&A section to start a new conversation.