

Latent Dirichlet Allocation (LDA) and Google's Rankings are Remarkably Well Correlated
Last week at our annual mozinar, Ben Hendrickson gave a talk on a unique methodology for improving SEO. The reception was overwhelming - I've never previously been part of a professional event where thunderous applause broke out not once but multiple times in the midst of a speaker's remarks.

_
Ben Hendrickson speaking in last Fall at the Distilled/SEOmoz PRO Training London
(he'll be returning this year)
_
I doubt I can recreate the energy and excitement of the 320-person filled room that day, but my goal in this post is to help explain the concepts of topic modeling, vector space models as they relate to information retrieval and the work we've done on LDA (Latent Dirichlet Allocation). I'll also try to explain the relationship and potential applications to the practice of SEO.
A Request: Curiously, prior to the release of this post and our research publicly, there have been a number of negative remarks and criticisms from several folks in the search community suggesting that LDA (or topic modeling in general) is definitively not used by the search engines. We think there's a lot of evidence to suggest engines do use these, but we'd be excited to see contradicting evidence presented. If you have such work, please do publish!
The Search Rankings Pie Chart
Many of us are likely familar with the ranking factors survey SEOmoz conducts every two years (we'll have another one next year and I expect some exciting/interesting differences). Of course, we know that this aggregation of opinion is likely missing out on many factors and may over or under-emphasize the ones it does show.
Here's an illustration I created for a presentation recently to help illustrate the major categories in the overall results:
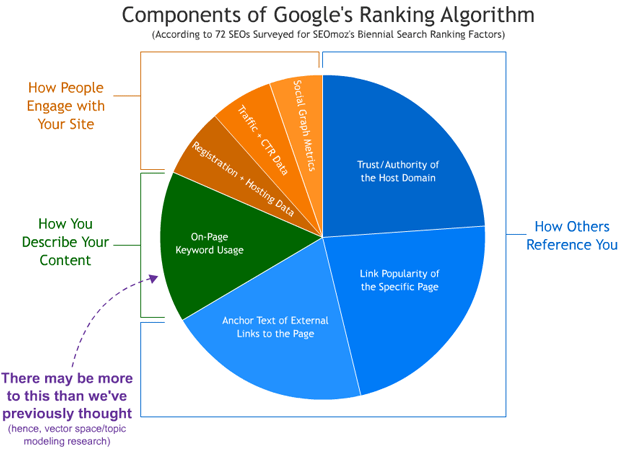
This suggests that many SEOs don't ascribe much weight to on-page optimization
_
I myself have often felt that from all the metrics, tests and observations of Google's ranking results, the importance of on-page factors like keyword usage or TF*IDF (explained below) is fairly small. Certainly, I've not observed many results, even in low competitive spaces, where one can simply add in a few more repetitions of the keyword, maybe toss in a few synonyms or "related searches" and improve rankings. This experience, which many SEOs I've talked to share, has led me to believe that linking signals are an overwhelming majority of how the engines order results.
But, I love to be wrong.
Some of the work we've been doing around topic modeling, specifically using a process called LDA (Latent Dirichlet Allocation), has shown some surprisingly strong results. This has made me (and I think a lot of the folks who attended Ben's talk last Tuesday) question whether it was simply a naive application of the concept of "relevancy" or "keyword usage" that gave us this biased perspective.
Why Search Engines Need Topic Modeling
Some queries are very simple - a search for "wikipedia" is non-ambiguous, straightforward and can be effectively returned by even a very basic web search engine. Other searches aren't nearly as simple. Let's look at how engines might order two results - a simple problem most of the time that can be somewhat complex depending on the situation.


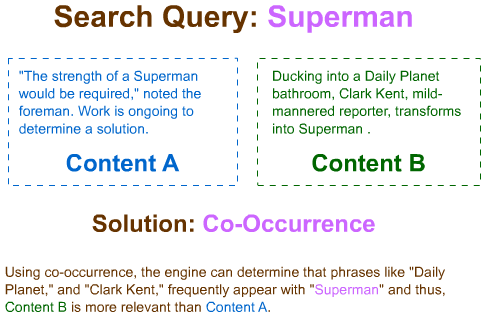

For complex queries or when relating large quantities of results with lots of content-related signals, search engines need ways to determine the intent of a particular page. Simply because it mentions the keyword 4 or 5 times in prominent places or even mentions similar phrases/synonyms won't necessarily mean that it's truly relevant to the searcher's query.
Historically, lots of SEOs have put effort into this process, so what we're doing here isn't revolutionary, and topic models, LDA included, have been around for a long time. However, no one in the field, to our knowledge, has made a topic modeling system public or compared its output with Google rankings (to help see how potentially influential these signals might be). The work Ben presented, and the really exciting bit (IMO), is in those numbers.
Term Vector Spaces & Topic Modeling
Term vector spaces, topic modeling and cosine similarity sound like a tough concepts, and when Ben first mentioned them on stage, a lot of the attendees (myself included) felt a bit lost. However, Ben (along with Will Critchlow, whose Cambridge mathematics degree came in handy) helped explain these to me, and I'll do my best to replicate that here:
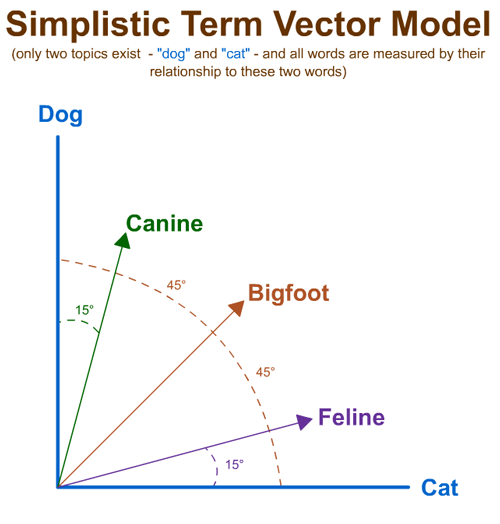
In this imaginary example, every word in the English language is related to either "cat" or "dog," the only topics available. To measure whether a word is more related to "dog," we use a vector space model that creates those relationships mathematically. The illustration above does a reasonable job showing our simplistic world. Words like "bigfoot" are perfectly in the middle with no more closeness to "cat" than to "dog." But words like "canine" and "feline" are clearly closer to one that the other and the degree of the angle in the vector model illustrates this (and gives us a number).
BTW - in an LDA vector space model, topics wouldn't have exact label associations like "dog" and "cat" but would instead be things like "the vector around the topic of dogs."
Unfortunately, I can't really visualize beyond this step, as it relies on taking the simple model above and scaling it to thousands or millions of topics, each of which would have its own dimension (and anyone who's tried knows that drawing more than 3 dimensions in a blog post is pretty hard). Using this construct, the model can compute the similarity between any word or groups of words and the topics its created. You can learn more about this from Stanford University's posting of Introduction to Information Retrieval, which has a specific section on Vector Space Models.
Correlation of our LDA Results w/ Google.com Rankings
Over the last 10 months, Ben (with help from other SEOmoz team members) has put together a topic modeling system based on a relatively simple implementation of LDA. While it's certainly challenging to do this work, we doubt we're the first SEO-focused organization to do so, though possibly the first to make it publicly available.
When we first started this research, we didn't know what kind of an input LDA/topic modeling might have on search engines. Thus, on completion, we were pretty excited (maybe even ecstatic) to see the following results:
Correlation Between Google.com Rankings and Various Single Metrics
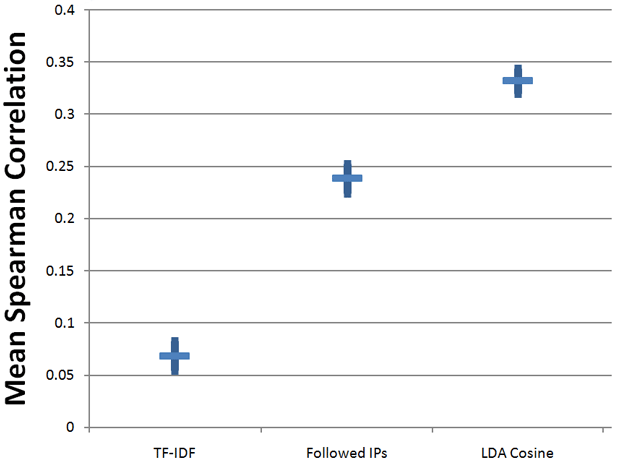
(the vertical blue bars indicate standard error in the diagram, which is relatively low thanks to the large sample set)
_
Using the same process we did for our release of Google vs. Bing correlation/ranking data at SMX Advanced (we posted much more detail on the process here), we've shown the Spearman correlations for a set of metrics familiar to most SEOs against some of the LDA results, including:
- TF*IDF - the classic term weighting formula, TF*IDF measures keyword usage in a more accurate way than a more primitive metric like keyword density. In this case, we just took the TF*IDF score of the page content that appeared in Google's rankings
- Followed IPs - this is our highest correlated single link-based metric, and shows the number of unique IP addresses hosting a website that contains a followed link to the URL. As we've shown in the past, with metrics like Page Authority (which uses machine learning to build more complex ranking models) we can do even better, but it's valuable in this context to just think and compare raw link numbers.
- LDA Cosine - this is the score produced from the new LDA labs tool. It measures the cosine similarity of topics between a given page or content block and the topics produced by the query.
The correlation with rankings of the LDA scores are uncanny. Certainly, they're not a perfect correlation, but that shouldn't be expected given the supposed complexity of Google's ranking algorithm and the many factors therein. But, seeing LDA scores show this dramatic result made us seriously question whether there was causation at work here (and we hope to do additional research via our ranking models to attempt to show that impact). Perhaps, good links are more likely to point to pages that are more "relevant" via a topic model or some other aspect of Google's algorithm that we don't yet understand naturally biases towards these.
However, given that many SEO best practices (e.g. keywords in title tags, static URLs and ) have dramatically lower correlations and the same difficulties proving causation, we suspect a lot of SEO professionals will be deeply interested in trying this approach.
The LDA Labs Tool Now Available; Some Recommendations for Testing & Use
We've just recently made the LDA Labs tool available. You can use this to input a word, phrase, chunk of text or an entire page's content (via the URL input box) along with a desired query (the keyword term/phrase you want to rank for) and the tool will give back a score that represents the cosine similarity in a percentage form (100% = perfect, 0% = no relationship).
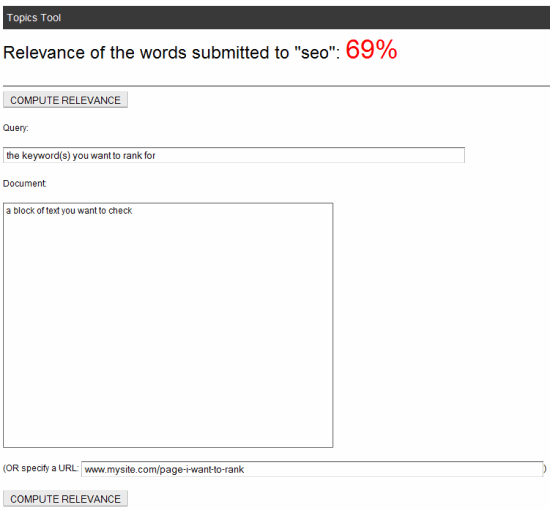
When you use the tool, be aware of a few issues:
- Scores Change Slightly with Each Run
This is because, like a pollster interviewing 100 voters in a city to get a sense of the local electorate, we check a sample of the topics a content+query combo could fit with (checking every possibility would take an exceptionally long time). You can, therefore, expect the percentage output to flux 1-5% each time you check a page/content block against a query. - Scores are for English Only
Unfortunately, because our topics are built from a corpus of English language documents, we can't currently provide scores for non-English queries. - LDA isn't the Whole Picture
Remember that while the average correlation is in the 0.32 range, we shouldn't expect scores for any given set of search results to go in precisely descending order (a correlation of 1.0 would suggest that behavior). - The Tool Currently Runs Against Google.com in the US only
You should be able to see the same results the tool extracts from by using a personalization-agnostic search string like http://www.google.com/xhtml?q=my+search&pws=0 - Using Synonyms, "Related Searches" or Wonder Wheel Suggestions May Not Help
Term vector models are more sophisticated representations of "concepts" and "topics," so while many SEOs have long recommended using synonyms or adding "related searches" as keywords on their pages and others have suggested the importance of "topically relevant content" there haven't been great ways to measure these or show their correlation with rankings. The scores you see from the tool will be based on a much less naive interpretation of the connections between words than these classic approaches. - Scores are Relative (20% might not be bad)
Don't presume that getting a 15% or a 20% is always a terrible result. If the folks ranking in the top 10 all have LDA scores in the 10-20% range, you're likely doing a reasonable job. Some queries simply won't produce results that fit remarkably well with given topics (which could be a weakness of our model or a weirdness about the query itself). - Our Topic Models Don't Currently Use Phrases
Right now, the topics we construct are around single word concepts. We imagine that the search engines have probably gone above and beyond this into topic modeling that leverages multi-word phrases, too, and we hope to get there someday ourselves. - Keyword Spamming Might Improve Your LDA Score, But Probably Not Your Rankings
Like anything else in the SEO world, manipulatively applying the process is probably a terrible idea. Even if this tool worked perfectly to measure keyword relevance and topic modeling in Google, it would be unwise to simply stuff 50 words over and over on your page to get the highest LDA score you could. Quality content that real people actually want to find should be the goal of SEO and Google's almost certainly sophisticated enough to determine the different between junk content that matches topic models and real content that real users will like (even if the tool's scoring can't do that).
If you're trying to do serious SEO analysis and improvement, my suggested methodology is to build a chart something like this:
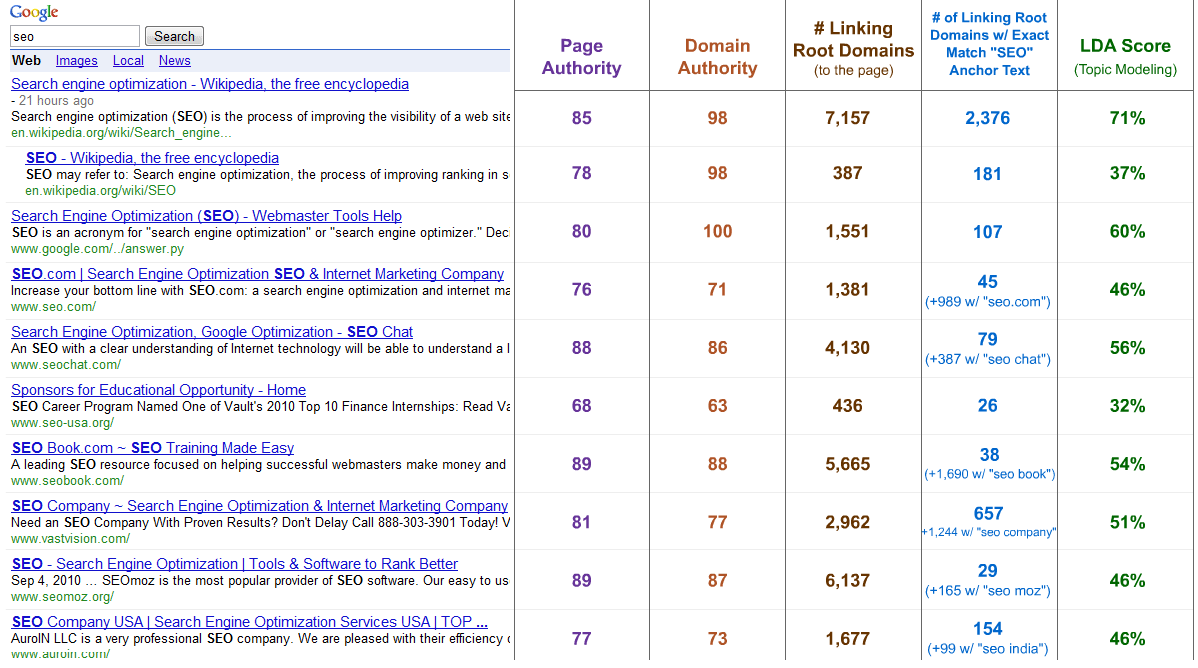
SERPs analysis of "SEO" in Google.com w/ Linkscape Metrics + LDA (click for larger)
Right now, you can use Keyword Difficulty's export function and then add in some of these metrics manually (though in the future, we're working towards building this type of analysis right into the web app beta).
Once you've got a chart like this, you can get a better sense of what's propping up your competitors rankings - anchor text, domain authority, or maybe something related to topic modeling relevancy (which the LDA tool could help with).
Undoubtedly, Google's More Sophisticated than This
While the correlations are high, and the excitement around the tool both inside SEOmoz and from a lot of our members and community is equally high, this is not us "reversing the algorithm." We may have built a great tool for improving the relevancy of your pages and helping to judge whether topic modeling is another component in the rankings, but it remains to be seen if we can simply improve scores on pages and see them rise in the results.
What's exciting to us isn't that we've found a secret formula (LDA has been written about for years and vector space models have been around for decades), but that we're making a potentially valuable addition to the parts of SEO we've traditionally had little measurement around.
BTW - Thanks to Michael Cottam, who suggested the reference of research work by a number of Googlers on pLDA. There are hundreds of papers from Google and Microsoft (Bing) researchers around LDA-related topics, too, for those interested. Reading through some of these, you can see that major search engines have almost certainly built more advanced models to handle this problem. Our correlation and testing of the tool's usefulness will show whether a naive implementation can still provide value for optimizing pages.
For those who'd like to investigate more, we've made all of our raw data available here (in XLS format, though you'll need a more sophisticated model to do LDA). If you have interest in digging into this, feel free to email Ben at SEOmoz dot org.
How Do I Explain this to the Boss/Client?
The simplest method I've found is to use an analogy like:
If we want to rank well for "the rolling stones" it's probably a really good idea to use words like "Mick Jagger," "Keith Richards," and "tour dates." It's also probably not super smart to use words like "rubies," "emeralds," "gemstones," or the phrase "gathers no moss," as these might confuse search engines (and visitors) as to the topic we're covering.
This tool tries to give a best guess number about how well we're doing on this front vs. other people on the web (or sample blocks of words or content we might want to try). Hopefully, it can help us figure out when we've done something like writing about the Stones but forgetting to mention Keith Richards.
As always, we're looking forward to your feedback and results. We've already had some folks write in to us saying they used the tool to optimize the contents of some pages and seen dramatic rankings boosts. As we know, that might not mean anything about the tool itself or the process, but it certainly has us hoping for great things.
p.s. The next step, obviously, is to produce a tool that can make recommendations on words to add or remove to help improve this score. That's certainly something we're looking into.
p.p.s. We're leaving the Labs LDA tool free for anyone to use for a while, as we'd love to hear what the community thinks of the process and want to get as broad input as possible. Future iterations may be PRO-only.
[ERRATA by Ben (sept 16th, 2:00pm PST): The blog post above reports the correlation measurement as 0.32. It should have been 0.17.]
The author's views are entirely their own (excluding the unlikely event of hypnosis) and may not always reflect the views of Moz.



Comments
Please keep your comments TAGFEE by following the community etiquette
Comments are closed. Got a burning question? Head to our Q&A section to start a new conversation.