

What Google Doesn't See CAN Hurt You (Update: But, in this case, it was cloaking)
It's been a big month for false positives and getting caught with spam, and I've never been one to break up a theme. Short post, but an important one that every dev team should be aware of.
The story starts with a smart SEOmoz member, Per Svanström, getting stumped by a perfectly legitimate, white hat subdirectory, with plenty of PageRank, dropping out of Google's index:
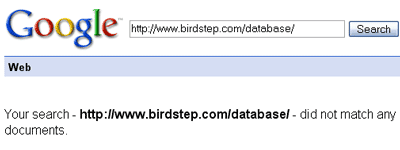
You can see from the image that the single URL was dropped, but a site:birdstep.com/database query reveals that in fact, all of those pages are out of the index. Time for some detective work.
Jane & I spent a few minutes trying to puzzle out if bad links were pointing in or if the pages were somehow cloaking or violating TOS. As we were digging through the backlink profile, we saw that, naturally, the birdstep.com domain was linking to the subdirectory on most every page. When we viewed the source code of those pages (for example, the homepage - www.birdstep.com), we saw something strange. Below is the tail end of the source code for their top nav bar:
<li class="menuObject"><a href="http://www.birdstep.com/Corporate/"><img src="/images/menu/Corporate.gif" border="0" alt="Corporate" /></a></li>
<li class="menuObject"><a href="http://www.birdstep.com/Contact-us/"><img src="/images/menu/Contact_us_active.gif" border="0" alt="Contact us" /></a></li>
<li class="menuObject"><a href="http://www.birdstep.com/database/"><img src="/images/menu/Database.gif" border="0" alt="Database" /></a></li>
Looks fine, right? Just a regular menu serving up images as the clickable link. Only problem is...

Notice the navbar? See the missing link? That's where the "database" section should be linked-to, only the image is missing. Apparently, it was just a design mistake and so they used a 1x1 pixel gif until they could get it fixed. There are plenty of other visible links in the content body of many pages over to the database section, but that top link in the navbar is invisible - technically violating Google's rules. Despite the fact that plenty of other sites and pages link to the database section legitimately, and Birdstep certainly has no reason or intention to hide that link (other than a miscalculation on pixel width), the whole subdirectory was removed from the index.
Luckily, we caught it, Birdstep has removed the link, and they'll hopefully have the subdirectory re-included in the near future. They also generously gave us permission to discuss the Q+A issue on the blog, which we very much appreciate. I think this serves as a wise warning to developers and designers everywhere - unintentional, white-hat spirited mistakes can be just as dangerous and have just as dire consequences as black hat manipulation. Watch your code!
One more point of interest - in searching around on this issue, I noticed that a Google search for http://www.birdstep.com/database/. (with the added period at the end) brought up this result:
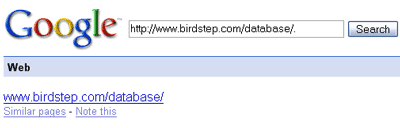
I ran another query on a page I know was removed from the index, and it also yielded a result like the one above (unfortunately, I can't share that page publicly). It's possible that this might help diagnose future pages that are removed for bad behavior and exhibit similar symptoms - definitely not a bad query to have in your arsenal if it really does work consistently.
UPDATE: Looks like although this hidden nav element could be a problem, it wasn't actually this issue coming into play here. The answer was... capital letters cloaking 404 pages to Google (an excellent find from John Mueller). Basically, Birdstep was using some user-agent and port detection to redirect Googlebot to a 404 error page (obviously, not an intentional, "we're cloaking because we want to trick Google," but the "oops, that was dumb" kind). The odd part is, it looks like Yahoo! and MSN/Live got it right (and there are plenty of links), but Googlebot was being treated differently.
We didn't notice this initially due to multiple problems - first, just switching your user agent to Googlebot in Firefox won't expose the issue. Neither will using search spider emulators like SEO-Browser. You need to actually telnet to Port 80 (as Matt Cutts notes in the comments). Second, you will see the page in Yahoo! and MSN (making it feel more like a penalty than a crawl issue). I seriously doubt they'll be banned for this - the intent to spam or deceive isn't there - but once again a fascinating detective story about the problems a site can have. Big thanks to Matt and to John for their help.
p.s. Removed the bottom part of the original post due to overwhelming feelings of sheepishness.
p.p.s. Dave Naylor has a tool that can help detect this sort of thing (though it wasn't originally intended for that use).
The author's views are entirely their own (excluding the unlikely event of hypnosis) and may not always reflect the views of Moz.



Comments
Please keep your comments TAGFEE by following the community etiquette
Comments are closed. Got a burning question? Head to our Q&A section to start a new conversation.