

12 Ways to Keep Your Content Hidden from the Search Engines
Here at Moz, we're usually talking about how to make your content more visible to the search engines. Today, we're taking a different direction. It may seem unusual, but there are plenty of times when content on your website needs to be protected from search indexing and caching. Why?
- Privacy
There are thousands of reasons to desire protection of your content from direct search traffic, from private correspondence to alpha products and registration or credential requirements. - Duplicate Content Issues
If you serve up content in multiple formats (print-friendly pages, Adobe PDF versions, etc.), it's typically preferable to have only a single version showing to the search engines. - Keyword Cannibalization
We've written a detailed post about how to solve keyword cannibalization, but in some cases, blocking spiders from accessing certain pages or types of pages can be valuable to help the process and ensure the most relevant and highest converting pages are ranking for the query terms. - Extraneous Page Creation
There are inherent problems with creating large numbers of pages with little to no content for the search engines. I've covered this before, talking about the page bloat disease and why you should eliminate extraneous pages. Si's post on PageRank also does a good job of showing why low-value pages in the index might cause problems. In many cases, the best practice with purely navigation or very thin content pages is to block indexing but allow crawling, which we'll discuss below. - Bandwidth Consumption
Concerns about overuse of bandwidth can inspire some site owners to block search engine activity. This can hamper search traffic unless you're cautious about how it's used, but for those extra-large files that wouldn't pull in search traffic anyway, it can make good sense.
So, if you're trying to keep your material away from those pesky spiders, how do you do it? Actually, there are many, many ways. I've listed a dozen of the most popular below, but there are certainly more. Keep in mind that tools like Moz Pro's Site Crawl will help you uncover many of them; you can check it out with a free trial if you're curious.
- Robots.txt
Possibly the simplest and most direct way to block spiders from accessing a page, the Robots.txt file resides at the root of any domain (e.g., www.nytimes.com/robots.txt) and can be used to disable spider access to pages. More details on the specifics of how to construct a robots.txt file and the elements within can be found in this Google Sitemaps blog post - Using a Robots.txt File and Ian McAnerin's Robots.txt Generator Tool can be very useful to save yourself the work of creating the file manually. UPDATE: I'm adding a link to Sebastian's excellent post on robots protocols and limitations, which gives a more technical, in-depth look at controlling search engine bot behavior.
- Meta Robots Tag
The Meta Robots tag also enables blocking of spider access on a page level. By employing "noindex," your meta robots tag will tell search engines to keep that page's content out of the index. A useful side note - the meta robots tag can be particularly useful on pages where you'd like search engines to spider and follow the links on the page, but refrain from indexing its content - simply use the syntax - <META NAME="ROBOTS" CONTENT="NOINDEX, FOLLOW"> - and the engines will follow the links while excluding the content. -
Iframes
Sometimes, there's a certain piece of content on a webpage (or a persistent piece of content throughout a site) that you'd prefer search engines didn't see. In this event, clever use of iframes can come in handy, as the diagram below illustrates:
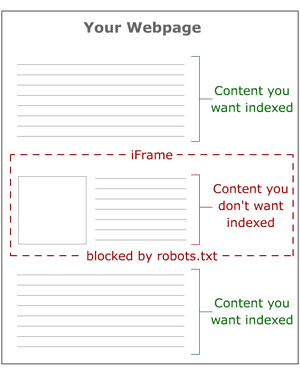
The concept is simple - by using iframes, you can embed content from another URL onto any page of your choosing. By then blocking spider access to the iframe with robots.txt, you ensure that the search engines won't "see" this content on your page. Websites may do this for many reasons, including avoiding duplicate content problems, lessening the page size for search engines, lowering the number of crawlable links on a page (to help control the flow of link juice), etc. - Text in Images
The major search engines still have very little capacity to read text in images (and the processing power required makes for a severe barrier). Thus, even after this post has been spidered by Google, Yahoo!, and Live, the word below will have 0 results:

Hiding content inside images isn't generally advisable, as it can be impractical for alternative devices (mobile in particular) and inaccessible to others (such as screen readers). - Java Applets
As with text in images, the content inside java applets is not easily parsed by the search engines, though using them as a tool to hide text would certainly be a strange choice. - Forcing Form Submission
Search engines will not submit HTML forms to attempt an access of the information retrieved from a search or submission. Thus, if you keep content behind a forced-form submission and never link to it externally, your content will remain out of the engines (as the illustration below demonstrates)

The problem, of course, is when content behind forms earns links outside your control, as when bloggers, journalists, or researchers decide to link to the pages in your archives without your knowledge. Thus, while form submission may keep the engines at bay, I'd recommend that anything truly sensitive have additional protection (through robots.txt or meta robots, for example). - Login/Password Protection
Password protection of any kind will effectively prevent any search engines from accessing content, as will any form of human-verification requirements like CAPTCHAS (the boxes that request the copying of letter/number combinations to gain access). The major engines won't try to guess passwords or bypass these systems. - Blocking/Cloaking by User-Agent
At the server level, it's possible to detect user agents and restrict their access to pages or websites based on their declaration of identity. As an example, if a website detected a rogue bot called twiceler, you might double check its identity before allowing access. - Blocking/Cloaking by IP Address Range
Similarly, IP addresses or ranges can be customized to block particular bots. Most of the major engines crawl from a limited number of IP ranges, making it possible to identify them and restrict access. This technique is, ironically, popular with webmasters who mistakenly assume that search engine spiders are spammers attempting to steal their content, and thus block the IP ranges to restrict access and save bandwidth.
- URL Removal
A secondary, post-indexing tactic, URL removal is possible at most of the major search engines through verification of your site and the use of the engines' tools. For example, Yahoo! allows you to remove URLs through their Site Explorer system, and Google offers a similar service through Webmaster Central. - Nofollow Tag
Just barely more useful than the twelfth method listed here, using nofollow technically tells the engines to ignore a particular link. However, as we've shown with several of the other methods, problems can arise if external links point to the URLs in question, exposing them to search engines. My personal recommendation is never to use the nofollow tag as a method to keep spiders away from content - the likelihood is too high that they'll find another way in. - Writing in Pig Latin
It may come as a surprise to learn that none of the major engines have a Pig Latin translator. Thus, if you'd like to keep some of your content from being seen in a search query, simply encode and publish :) For example, try searching for the English version of the following phrase and you'll see no results "Elcomeway otay Eomozsay Istermay Orgelsprockenmay!" (at least, until someone translates it in the comments below).
Hopefully these tactics can help you understand the best ways to hide content from the engines effectively. As always, feel free to chime in with comments, questions, or opinions.
The author's views are entirely their own (excluding the unlikely event of hypnosis) and may not always reflect the views of Moz.



Comments
Please keep your comments TAGFEE by following the community etiquette
Comments are closed. Got a burning question? Head to our Q&A section to start a new conversation.