

A Universe of Graphs
Sometimes, we have to look at things from far away to really understand them.
Sequence from Contact by Robert Zemeckis, distributed by Warner Bros.
Ever since I can remember, I have loved astronomy and science fiction. When I was a kid in the 70s (yes, I'm older than most of you), the space adventure was still something mythical; men were driving the Moon Buggy, Viking 1 and 2 sent the first pictures from Mars; the Pioneer 10 had been just sent to the boundaries of the Solar System with its famous golden plaque (our message in a bottle for those who might receive it); and Carl Sagan was presenting Cosmos: A Personal Voyage on PBS.
Perhaps it is for that passion that when I saw the graphic representation of the Internet for the first time, a question came to mind: what if the visualization of the universe and of the web are more similar than we think?

(Visualization of Internet - Credits: Opte.org)
I know it's a metaphor - one of many - but perhaps it is the most effective among those we have available.
One thing is clear: we should be aware that the universe is not only what we see with our eyes, and there is no one law that commands it; and so it is with the web, and especially with Google.
Gravity, relativity, and quantum theories are some of the laws that govern the universe we know. Physical and mathematical laws that translate into formulas and algorithms, as well as algorithms and graphs, are what govern the Google universe.
In this post, I invite you to put on your astronaut suit and travel with me through the universe of Google on a mission to understand how, perhaps, it works.
Before we go, a space travel needs a soundtrack, always:
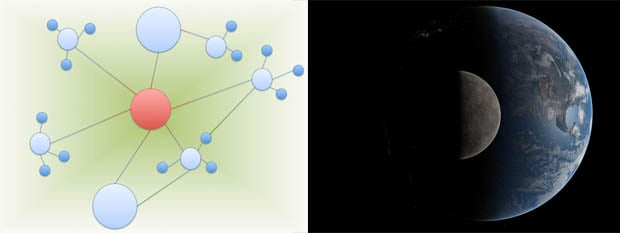
Home: Earth

Our site, our Earth. A blue dot in the darkness. Isn't it beautiful seen from space?
Yet Earth is the only one of nine planets in our solar system where life could have evolved to a sentient state.
But, if Earth was out of the so-called "habitable zone," life as we know it would not have been possible.
The same is true with our websites; our online homes.
An incorrect navigation architecture and crawlers won't be able to index the whole site. An bad use of robots.txt, of rel="canonical", and of the meta robots tag (or simply, the use of an incorrect design) and important parts of a website will be as invisible as the dark side of the moon.
These incorrect points and countless others especially related to user experience (speed, heavy ad presence, duplicated and thin content, etc.) or to what may correctly explain to crawlers what a page is about (for instance, structured data) are those things that make our website "uninhabitable" in the eyes of the search engines.
These algorithms - we'll refer to them as the "technical graph" for convenience - are what Google uses to determine if a site is habitable, just as scientists measure the presence of oxygen, water, seasons, and many others things when considering if a planet has the ability of hosting life.
A habitable zone is a prerequisite that, without, with we cannot even think to start our journey. This alone should help us understand how technical SEO is and still will be an essential element in our plans as Internet marketers.
SearchLove Boston 2013 by Will Critchlow, Technical SEO from Distilled
The beginning of the journey: the Link Graph
Did you know that life on Earth might not have been possible without the Moon? At least, this is what many scientists affirm. But even without going to that extreme, it seems certain that our giant satellite has played a role in the creation of life.
Similarly, in the universe of Google, a site cannot be considered habitable without the influence of a key external factor: the Link Graph.
The Link Graph is the representation of the relation between web pages (Nodes) through links (Edges).
There is an "internal" Link Graph which exists in the connections between pages of the same Pay-Level Domain (domain.com) and Fully Qualified Domain Names (commonly called subdomains, as it is www.domain.com) and an external one, which is based on the connections via backlinks between pages of different domains and that we normally call the "Link Profile."
One of the laws ruling the Link Graph of the Google universe is the PageRank algorithm.
In the PageRank algorithm (explained in the least complicated way possible), a link to a page counts as a vote of support.
The PageRank of a page, then, is defined recursively and depends on the number and PageRank of all the pages that link to it ( also known as "backlinks").
Therefore, a page that is linked to by many pages with high PageRank will, in turn, have a high PageRank. If a page has low-value backlinks or no backlinks at all, then it will have low PageRank or PageRank zero.
Apart from the page level PageRank, there is also a Domain PageRank, which is the aggregate value of all the single PageRanks of the pages of a site. It explains why having a link from a page with low PageRank, but great Domain PageRank can be better than having a link from a page with a relatively better PageRank, but a worse Domain PageRank.
.jpg "Schematic representation of the Link Graph - Internal and External")
PageRank (which technically is a query-independent ranking model) isn't the only factor that plays a role in the link graph. There is also a second mode of connectivity based-ranking, this time query-dependent has a major role. This mode is based on the HITS algorithm, which declares that a document which points to many others might be a good hub, and a document that many documents point to might be a good authority. Recursively, a document that points to many good authorities might be an even better hub, and similarly a document pointed to by many good hubs might be an even better authority, as Monika Henzinger of Google explained (quote from Search Quality: The Link Graph Theory by Dan Petrovic).
SEOmoz ( now Moz) is a good example of a site which responds positively to both algorithms. To PageRank, because it has more than 6 million backlinks from 40,843 unique domain names (OSE data before the migration to Moz.com), and to HINT, because it is both a hub and an authoritative site according to that algorithm.
The problem of PageRank and the HINT Algorithm is that they can be altered artificially using manipulative techniques.
For that reason, a great part of the Google updates' history is the tale of Google fighting the effects of those techniques to keep its mission: presenting only the best results in the SERPs.
One update was assigning a value to a link depending from what section of a web page (header, sidebar, footer, "body") that same link is published
And this is why we have seen changing so many times the so-called ranking factors related to the link profile.
What are the factors related to the Link Graph that are taken into consideration by Google now? No one knows for sure, and SEOs can only reasonably guess through correlation studies.
The latest one was presented by Searchmetrics during the last edition of SMX London in May (and Rand announced Moz is cooking a new edition of their Ranking Factors in time for MozCon). Very few factors presented were directly related to backlinks:
Searchmetrics Ranking Factors - Backlinks
| Factor | Spearman Correlation value |
|---|---|
| Number of backlinks | 0.34 |
| % Backlinks with Keywords | 0.08 (diminishing value) |
| % Backlinks rel="nofollow" | 0.23 (increasing value) |
| % Backlinks with Stopword | 0.17 (increasing value) |
While we wait for the publication of both the complete report by Searchmetrics and the new Ranking Factors study by Moz, here you can find:
Why is it important to know how the Link Graph works? Because even though the power of backlinks in the Link Graph is diminishing, by percentages, it is still the most important factor in the Google algorithm. Knowing how it works and what makes a link graph of a site a good or bad is essential for the success of a site, and Penguin is here to prove it.
It also tells us very clearly how being an hub and/or an authoritative site prizes in the Link Graph, hence we should create and establish strategies aimed at making our sites the best resource and the thought leader in our niche. As you will see, this principle is also at the base of other graphs, which have an influence in shaping the universe of Google, because, yes, the Link Graph is not the only one exercising a force capable of conditioning that universe.
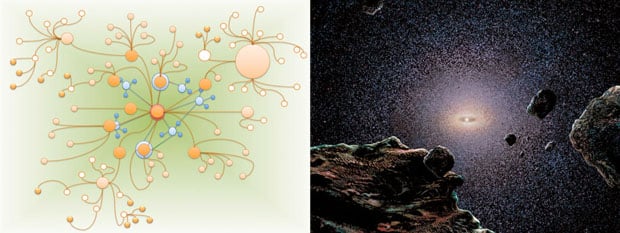
The edge of the solar system: the Social Graph
At the edge of the solar system, at such a distance that the Sun is just a little bigger than the other stars of the firmament, we find the Oort Belt, from which the comets come from.
What we see from so far away is a solar system in which Earth is only a small element, influenced by all the others that orbit the Sun and that affect the nature of our planet.
Similarly in the universe of Google, our site is surrounded by elements that directly or indirectly influence it. And the Social Graph is one of them.
Content is not just shared and endorsed by backlinks. On the contrary; right now, links play a smaller role compared to social media in how things are spread online. Back in 2010, this was quite evident already, so much that I remember Rand Fishkin sharing research at ProSEO London (now Distilled Searchlove) that he did about how social sharing, especially tweets, was slowly but firmly substituting the act of linking out.
We are no longer citing "Linkeratis," but influencers and thought leaders as the most important targets of our SEO outreach actions.
The mathematical visualization of the relations between Internet users via their social profiles (the nodes of the graph) is what we know as Social Graph, a term that was popularized in 2007 by Mark Zuckerberg.
Web pages can also be considered nodes of the Social Graph, thanks to protocols like the Open Graph.
The edges of these social relations can be many things; like a tweet, for instance. And it just so happens that a social share most of the times include a link.

Before answering the question that many of you may be thinking, remember that I am writing about the Google universe and not about social media itself as an inbound marketing channel, even though - being an Inbound Strategist - I consider it essential for the success of a site.
And now the question: does the Social Graph influence how the Google universe works? My answer is: not directly, but indirectly, yes.
The answer is not directly because:
- Google doesn't have direct access to all of the Social Graph of any single page/site/profile, as it is partially blinded when looking at it. For instance, take a look at Facebook and Twitter. Google must rely on what the page first allows it to partially crawl and rank (i.e. the Facebook Pages main page) or on what it can discover indirectly with crawling sites like Topsy (in the case of the Twitter statuses).
- The Social Graph generated by Google Plus and +1s is still not a fully trustful representation of the main Social Graph.
This means that, even though Google assigns a PageRank value to the social profiles or could somehow understand if a profile is a hub and/or an authority, it cannot consider the information it owns as totally reliable. More over, Google can't definitely understand if a Facebook or Twitter profile is fake or has artificially grown his followers/fan base (and, honestly, it seems having problems in understanding it in its own Google Plus).
Finally, many profiles and brands who actually are big nodes in the Social Graphs are not present in Google Plus, or are not as far active as they are in other social networks.
But the answer can be also a yes, because:
- Social signal seems to have a strong role in Freshness, the algorithm of Google that prizes the freshest and popular content for a determined set of queries, which requires the most up to date information sources (i.e.: News);
- A correlation between a richer social graph profile of a page and its rankings seems been proved by several correlation studies conducted over the past two years.
In fact, the more a piece of content is shared socially, the bigger the probabilities are that the content obtains natural links, as visually explained in the short animation here below (red is our site, blue is the sites that link to it, and orange/green are the nodes of the social graph generated by the site). Social Echo has an impact in the Google universe.
It is very easy to understand why social media is important for SEO; the healthier the Social Graph of a site is, the higher the chance that even its Link Graph is. Therefore, that site's visibility in Google search results will be better.
What are the social signals that now have the best correlations in respect to Google rankings?
Marcus Toder of Searchmetrics answered to this question in his previously cited speech at SMX London this year:
Searchmetrics Ranking Factors - Social Signals
| Factor | Spearman Correlation value |
|---|---|
| Google +1 | 0.36 |
| Facebook Shares | 0.32 |
| Facebook Total | 0.32 |
| Facebook Comments | 0.30 |
| Facebook Likes | 0.29 |
| Tweets | 0.26 |
| 0.25 |
In the past days, I asked to Steve Lock and James Chant of Linkdex to create for this post the Social Graph (albeit partial) of Rand and Matt McGee with their Mention Graph tool and the result and the result is this:

As kindly James explained to me:
Looking at the Network Analysis, we can see a small section of the SEO community and how they're connected. The circular ‘nodes’ denote the people in the network, the size denoting how influential they are. These can be selected too – like Matt McGee in the example – to reveal more information about that person, including the domains they link from and to, their social profiles, recent content and more.
The lines show how they’re connected. If an arrow points from @randfish to @richardbaxter then it means Rand influences Richard. Using filters you can start to look for the most influential people and understand the best way to spread your message around the network. This is about being more efficient in your outreach, since lists are no longer the optimal way to understand a network of people.
You can you also tools like Gephi and NodeXL in create and analyze the Social Graph (or the Link Graph).
But we should not look to social media just as a channel for gaining links, but as:
- A way to expand the recognition of our site as a hub and authority;
- A channel that allows those who are becoming thought leaders the ability to share our knowledge with others - even our competitors - who will respect, search, and cite;
- A strategical discipline which helps us become a named entity recognized by Google.
Entity recognition (with citation), knowledge base, personalization, and localization play an essential role in the ecosystem of the universe of Google.
The Dark Matter and Dark Energy: the intangible graphs of the Google universe
The Planck Mission Team has calculated that, accordingly to the standard model of the Big Bang Cosmology, the ordinary matter "we see" accounts for just 4.9% of the total mass of the Universe. All the rest is Dark Matter (26.8%) and Dark Energy (68.3%). Without them, we would not be able the explain the nature of the Universe.
Similarly, when we try to understand how the Google universe works, not all can be explained with the "technical" Link and Social Graphs. In the Google universe, too, there are different kinds of dark matters and a dark energy that influence it.
.jpg)
Entity recognition and Knowledge Base
Google can classify the documents of the web thanks to the Link Graph and, possibly and potentially, the Social Graph. The documents themselves can explain their own nature with what I defined as the "Technical Graph."
Google then fills the vacuum between documents with the information stored in its own Knowledge Base, the dark energy of the Google universe, which is the information repository Google has built and endlessly builds by crawling the web. It is able to access this repository from the same searches done by the users and the "attention graph" generated by them, as it was defined by Bill Slawski in a Twitter conversation we had.
Knowledge Base helps Google with providing answers to how and why the documents are connected and searched, and an understanding of what named entities those same documents cite and are related to.
But...what is a named entity?
The Query Rewriting with Entity Recognition patent by Google define a named entity as something that may refer to anything that can be tagged as being associated with certain documents. Examples of entities may include news sources, stores, such as online stores, product categories, brands or manufacturers, specific product models, condition (e.g., new, used, refurbished, etc.), authors, artists, people, places, and organizations.
How might Entity Recognition work? Justing Briggs (in this post written a year ago, but still incredibly relevant) explained it with a very easy to understand example:

Entity recognition, relationships between entities, and the authority values Google may assign to specific sets of entities (i.e. authors, but also publishers), thanks to a combination of Entity Search, Link Graph, and Social Media metrics, leads to the opportunity of:
- Creating content that is not just amazing, but consistently responds to the entity searches users may create.
- Creating bonds with entities (both with authors and publishers) Google may consider authoritative over a specific topic or entity categorization.
- Relying not just on links, but also on co-citations and co-occurrences.
Co-citations and co-occurrences
Last November, Rand presented a Whiteboard Friday that included three examples of sites which were ranking for very competitive keywords without having really a strong link profile with those keywords as anchor text, or even ranking for a page (the home page, in his example) that was not optimized for the keyword it was ranking for.
The reason was possibly to be found in co-citations and co-occurrences.
Using the graphic representations Haris Basic created for his post on Search Engine Journal about this topic, we can explain co-citation this way:

As we can see, the association of two entities (sites B and C) with no relation in the Link Graph is generated by a site linking to both.
Somehow, this is a syncretic combination of Link Graph and Entity Recognition, and the entity association will have a stronger force as stronger is the value of Site A both as a hub and authority.
Co-occurrences, instead, can be explained this other way:

Co-occurrences assign a query value to the content associated to an Entity by a document. The examples cited by Rand in his Whiteboard Friday seem to fall more into this typology of "dark matter," which is totally independent from the Link Graph.
Do "spam" co-occurrences exist? Yes. But it's probable that co-occurrences by themselves would not be able to consistently influence rankings without a combination of other positive metrics from other graphs. This could be the same as the PageRank and Domain PageRank of a site citing but not linking another, its HINTS values, its Social Graph metrics, and its Entity grade. This combinatory mechanism is something we should always keep in mind, and never consider one factor being the king of all.
Author Graph (better known as AuthorRank)
Among the "dark matter" of the Google universe, there is one item that fits perfectly and complements the ones we have cited before, as it is – somehow – a specialized extension of the concept of Entity: the Agent Rank.
Agent Rank is described in a patent Google has updated several times after its first publication in 2007, but it was more a loved by patent experts topic than something SEOs were seriously paying attention to… at least until 2011, when Google announced the Authorship program and started acquiring startups like Social Grapple and PostRank, or when the real nature of Google Plus as a profiler tool became more obvious. It was only in that moment that SEOs started inferring and “invented” the concept of AuthorRank, that none better than AJ Kohn was able to define: "AuthorRank means that your reputation as a content creator will influence the ranking of the search results. Not only that but AuthorRank can be used to make the link graph more accurate. AuthorRank combines the web of people with the web of links to create a more savvy view of trust and authority that will be used to rank search results."
Again, like co-citations, AuthorRank seems to be an Entity-based factor influencing the Link Graph.
But there is a problem:
AuthorRank is not a ranking factor yet. The percentage of use of the rel="author" is still very low, even though Agent Rank should become so sooner rather than later.

Nonetheless, it's suggested to work as if AuthorRank is already here because:
1. It is a good investment for the future
2. It already offers great benefits
We should start by implementing the rel=”author” mark up, because it has an effect on CTR and because it is not used in many competitive industries quite yet.
Pro tip: We should try to use authorship with well-known and respected personalities within our niche as authors, because not every person causes the same effect, and because – in the future – the more authoritative the author is, the more authoritative the publisher will be considered.
We can use the Author data in Google Webmaster Tools to analyze what content we or our authors can create for the desired reception of our audience, and we should take advantage of the “Author Search” in SERPs functionality the authorship discloses.
We must engage with other authors, especially on Google Plus, and use it as a channel through which we can become a trusted source of information and a thought leader (again!). We should start offering the Google Plus Sign In and Google Plus comments options on your site. We should be more active in the G+ Communities.
All these actions already offer a direct and measurable benefit, but they will also help us gaining a competitive advantage whenever AuthorRank becomes an active player in the Google universe. We should take all these actions because they seem to have a reflection in the new search multiverse Google has created, and it will probably be its future: the Knowledge Graph.
Multiverse: the Knowledge Graph
Nothing is as terrifying in space as a black hole. A black hole is a super massive star which collapsed into itself, with such a density that light can't escape it and such a strong gravity pull that it absorbs everything passing its event horizon.
But black holes are usually considered the best candidates for doubling as wormholes, a tunnel that may fold space so to potentially connect very distant parts of it, and also become a connection between two totally different universes.
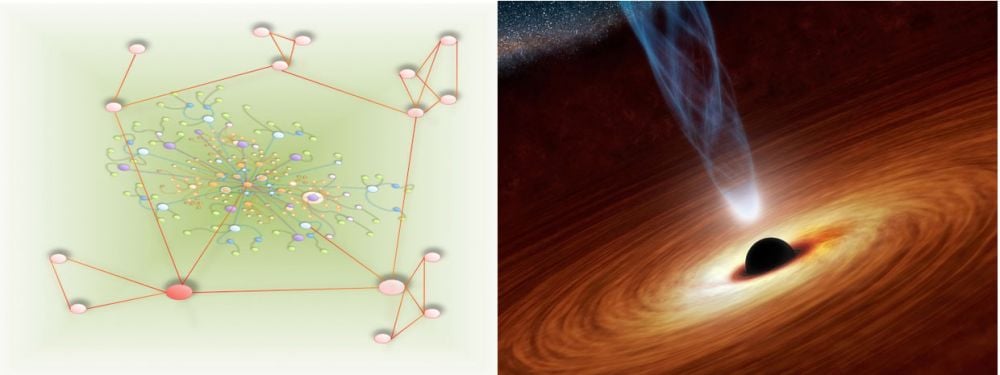
Entity recognition and Knowledge Base are the foundations of the Knowledge Graph.
Shashi Thakur - the chief of the Knowledge Graph project - defined it as a “now query-less interface” in this illuminating post on Memeburn. Being query-less, the Knowledge Graph pushes information without us asking explicitly for it.
It tries to satisfy our information needs about a topic, offering itself as a guide for a deeper investigation about it and - especially in a mobile environment - reasonably guesses what we are really looking for thanks to the direct knowledge Google has of our geo-location, search history, and even of our Calendar and Gmail content.
In this sense, the Knowledge Graph seems like the answer to the desire Larry Page expressed about making of Google a tool, which w ould give you answers to things that matter to you -- even when you didn't ask (more here).
How does the Google multiverse of the Knowledge Graph work?
In the Knowledge Graph, based on a technology first developed by Metaweb (now part of Google), Entities are nodes. The edges linking the nodes are the associations they have one each other based on information retrieval.
For instance, the named entity “Renaissance” is linked to people (Leonardo, Michelangelo, Raphael, etc.), things (The Last Supper, Mona Lisa, etc.), books (The Prince and others), and so on.

A very recent patent, well explained by Bill Slawski, describes what kind of content can be used in the Knowledge Graph box.
Let’s check some of them visually
The patent cited above affirms that videos and sound bits are also previewed as elements, which can be presented in the Knowledge Graph box.
But where does Google pick up all the information presented in the Knowledge Graph Box?
Open and Linked Data (Wikipedia above all, but not just Wikipedia) and Google's own Knowledge Base. Knowledge Base in particular influences what information is presented both in the the central section of the box and in the carrousel below, and that corresponds to what people search.
However, Google also collects information from the structured data (Schema.org and Open Graph) it crawls. This is quite clear when we have Knowledge Graph boxes with events listed:
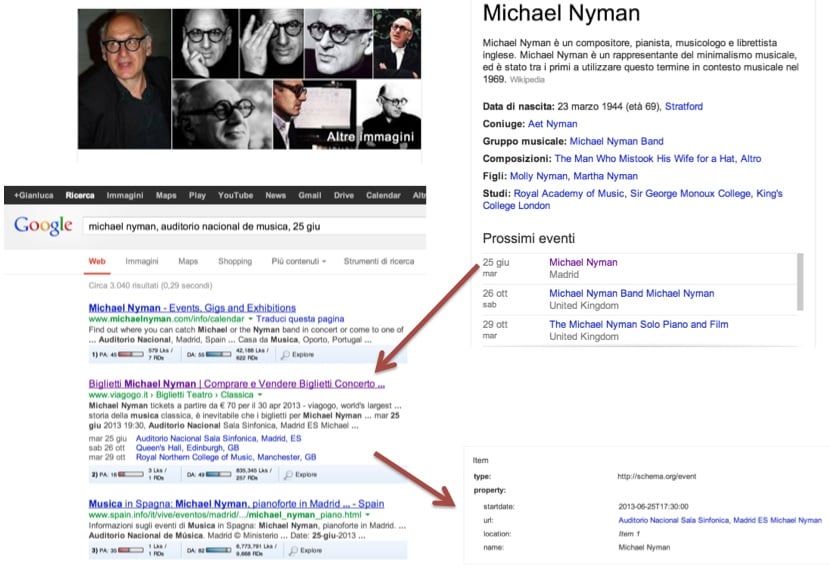
You can find more observations and discoveries about the Knowledge Graph in this deck I presented in the last edition of the ISS SMX in London few weeks ago.
The Knowledge Graph (which actually is considered by many SEOs to be a curiosity because it can't be "appropriately" SEOd) is something every Internet marketer should start studying and understanding very well, because it is what Google is going to become.
Adding more complexity
When we look at the stars, we are observing the past. Our position in space, the light years that separate Earth from those stars, and the time their light needs to reach us explain that assumption.
But our observation is also based on our knowledge. For instance, the lines on the Mars surface that Schiapparelli thought were canals maybe created by intelligent form of life, modern astronomy proved weren't canals at all. Similarly in the Google universe, everything we experience is influenced by our geo-location and personalized by our history search, and our knowledge.
Those two conditions are so pervasive and strong right now that it is not so crazy to think that, in the future, everyone will experience a unique search experience completely different from the one of another person, and that the so-called "neutral search" will be the exception - or maybe just the beginning - of our personal voyage in the Google universe.
Conclusion
Sometimes, we have to look at things from far away to really understand them.
The author's views are entirely their own (excluding the unlikely event of hypnosis) and may not always reflect the views of Moz.



Comments
Please keep your comments TAGFEE by following the community etiquette
Comments are closed. Got a burning question? Head to our Q&A section to start a new conversation.