

Googlebot Crawl Issue Identification Through Server Logs
The author's views are entirely their own (excluding the unlikely event of hypnosis) and may not always reflect the views of Moz.
Sifting through server logs has made me infinitely better at my job as an SEO. If you're already using them as part of your analysis, congrats - if not, I encourage you to read this post.
In this post we’re going to:
- Briefly introduce a server log hit
- Understand common issues with Googlebot's crawl
- Use a server log to see Googlebot's crawl path.
- Look at a real issue with Googlebot wasting crawl budget and fix it.
- Introduce or reacquaint you with my favourite data analyzer.
It’s critical to SEOs because:
- Webmaster tools, 3rd party crawlers and search operators won’t give you the full story.
- You’ll understand how Googlebot behaves on your site, and it will make you a better SEO.
I’m going to casually assume that you at least know what server logs are and how to obtain them. Just in case you've never seen a server log before, let's take a look at a sample "hit".
Anatomy of a server log hit
Each line in a server log represents a "hit" to the web server. The following illustrations can help explain:

File request example: brochure_download.pdf

A request for /page-a.html will likely end up with multiple hits because we need to get the images, css and any other files needed to render that page.
Image credit: Media College
Example hit
Every server is inherently different in logging hits, but they typically give similar information that is organized into fields. Below is a sample hit to an Apache web server, and I've purposely cut down the fields to make this simpler to understand:
50.56.92.47 - - [31/May/2012:12:21:17 +0100] "GET" - "/wp-content/themes/esp/help.php" - "404" "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)" - www.example.com -
| Field Name | Value |
| IP | 50.56.92.47 |
| Date | 31/May/2012:12:21:17 +0100 |
| Method | GET |
| Response Code | 404 |
| User-agent | Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) |
| URI_request | /wp-content/themes/esp/help.php |
| Host | www.example.com |
In reality, there are many more fields and a wealth of information that can only be gained through web server logs.
Googlebot crawl issues you can find with logs
Specifically in regards to SEO, we want to make sure that Google is crawling the pages we want to be crawled on our site - because we want them to rank. We already know what we can do internally to help pages rank in search results, such as:
- Ensure the pages are internally linked.
- Keep important pages as close to the root as possible.
- Ensure that the pages do not return errors.
This is all typically standard stuff and you can get this information easily without server logs, but I want more, I want to see Googlebot.
I want to look for Googlebot specific issues like:
- Unnecesary crawl budget expenditure
- Page it considers important / not important
- If there are any bot traps
- Is Google making up 404 errors by trying to make up URLs (think JavaScript)
- Is Google trying to fill out forms? (Yes, it happens)
Using server logs to see Googlebot
Step 1: Get some server logs.
Ask your client, or download a set of server logs from your hosting company. The point is to try and capture Googlebot visiting your site, except we don’t know when that’s going to happen – so you might need a few days worth of logs, or just a few hours.
To give you a real example:
Example domain has a PageRank of 6, DA of 80 and receives 200,000 visits a day. Their IIS server logs will amount to 4gB a day, but because the site is so popular, Googlebot visits at least once a day.
In this case, I would recommend a full day worth of logs to ensure we catch Googlebot.
Step 2: Download & Install Splunk.
Head over to http://www.splunk.com, sign up and download the product – free edition.
Note: the free edition will only let you upload 500mb per 24 hours.
Step 3: Adding your server log data to Splunk
I would recommend that you put your server logs on you local machine to make this process nice and easy.
I've put together a quick few screencasts, I know they sound cheesy, but whatever.
Step 4: Only displaying hits containing Googlebot as the user-agent
Step 5: Export to Excel
Simply click on the Export link and wait for your massive CSV to download. (Note: If the link doesn't appear, it's because the search isn't finished yet)
The Analysis, problem & the fix
The problem
Every time Googlebot came by the site, it spent most of it's time crawling PPC pages and internal JSON scripts. Just to give you an idea of how much time and crawl budget was wasted, please see below:
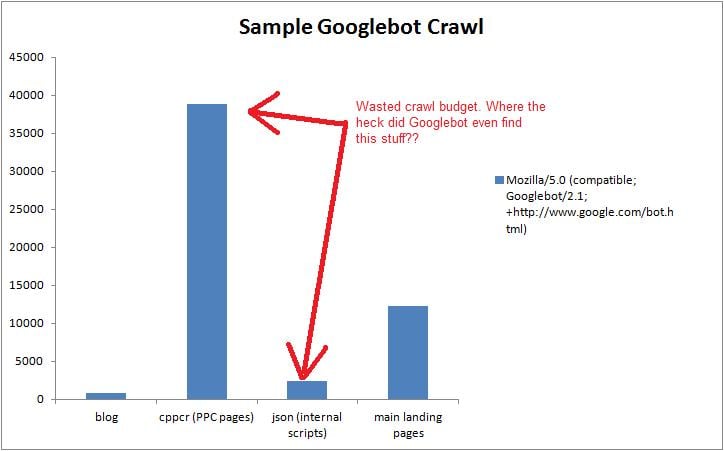
The real problem is that we had pages on the site that hadn't been indexed, and this was the cause. I wouldn't have found this without the server logs and I'm very grateful I did.
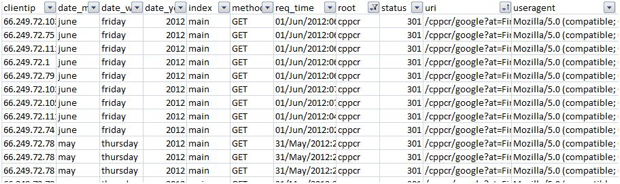
A look into my Excel spreadsheet
How to confirm what you're seeing is actually Googlebot
It's possible to crawl or visit a site using the Googlebot user agent, and even worse - it's possible to spoof the Googlebot IP. I always double check a list of IPs to what I see in the server log report and I use the method officially outline by Google.
How did I fix this?
1) Crawling PPC pages
I checked that these pages weren't indexed or receiving any traffic first, then I used robots.txt to block only Googlebot from these pages. I was very careful about this since I wanted to make sure that I didn't block Google Adbot (the robot that needs to crawl PPC pages).
User-agent: Googlebot Disallow: /*/cppcr/ Disallow: /cppcr
2) Infinite GET requests to JSON scripts
This was just another simple robots.txt block because Google didn't need to request these scripts. Googlebot basically got caught in a form, over and over again. Realistically, there's no reason for any bot to crawl this, so I set the user-agent to all (*).
User-agent: * Disallow: /*/json/ Disallow: /json
Results
I'm pretty happy to say that a week later, there was an increase of 7,000 pages in the index as reported by Webmaster tools.
Rand wrote about some good tips to prevent crawling issues, so I recommend you checking it out, as well as special thanks to the folks at ratedpeople.com for being kind enough to let me analyze and experiment on their site.
Additional resources
- Splunk documentation
- Apache server log documentation
- Enabling IIS logging
- cPanel server log downloads
- Differences between hits & pageviews
Feel free to follow me on Twitter @dsottimano, don't forget to randomly hug a developer - even if they say they don't like it :)



Comments
Please keep your comments TAGFEE by following the community etiquette
Comments are closed. Got a burning question? Head to our Q&A section to start a new conversation.